
The Scale Cube
A Thoughtful Approach to Application Scaling


Scaling isn’t just about throwing more machines at a problem. It’s about architectural thinking.
The Scale Cube emerged from "The Art of Scalability" as a deceptively simple yet profoundly useful model for thinking about application scaling. Rather than approaching scalability as a chaotic collection of techniques and technologies, the Scale Cube provides a structured way to understand your options across three distinct dimensions.
What makes the Scale Cube particularly valuable is its recognition that scalability isn't a single problem with a single solution. Instead, it acknowledges that different types of growth create different types of pressure on your system, and these different pressures require different approaches. The model organizes these approaches into three axes: X, Y, and Z, each representing a fundamentally different strategy for handling increased load.
Whether you're building distributed systems, designing microservices, or preparing for a system design interview, the Scale Cube gives you a powerful mental model to navigate the complexity of scaling.
Let’s unpack it.
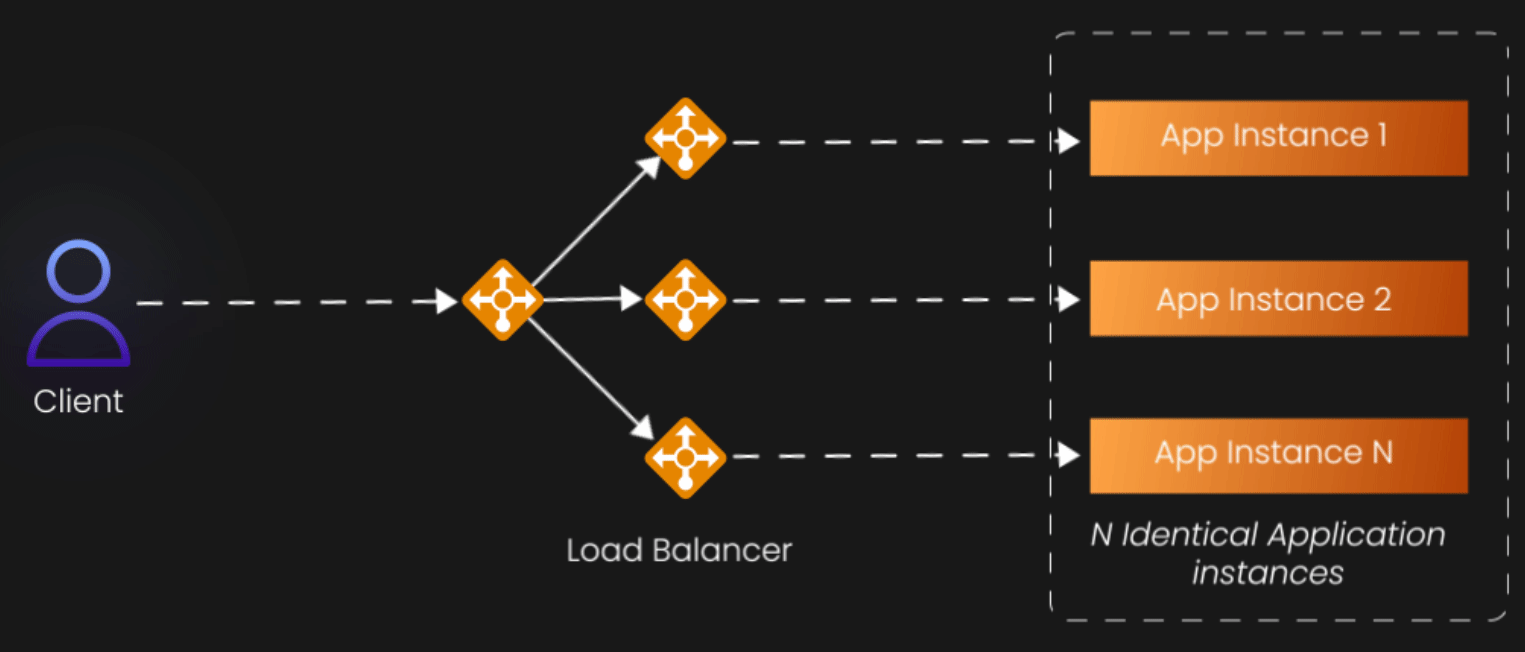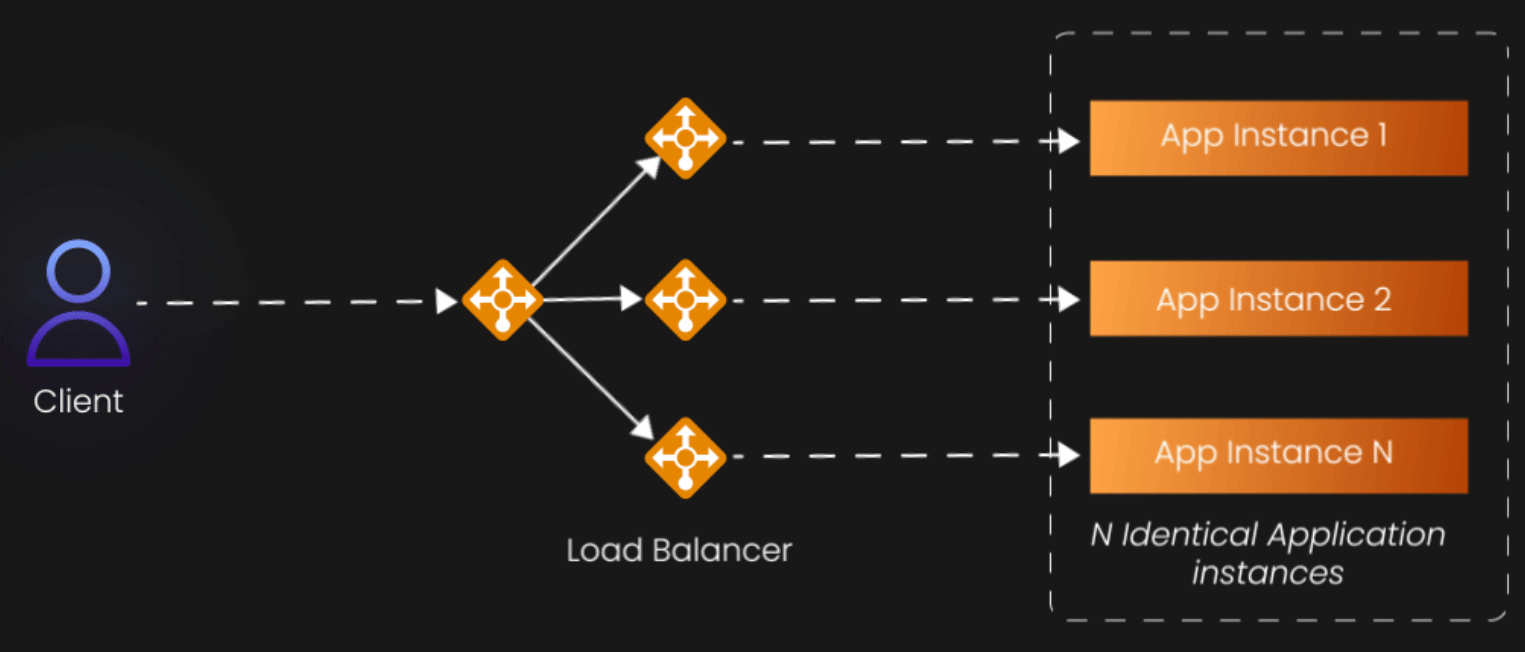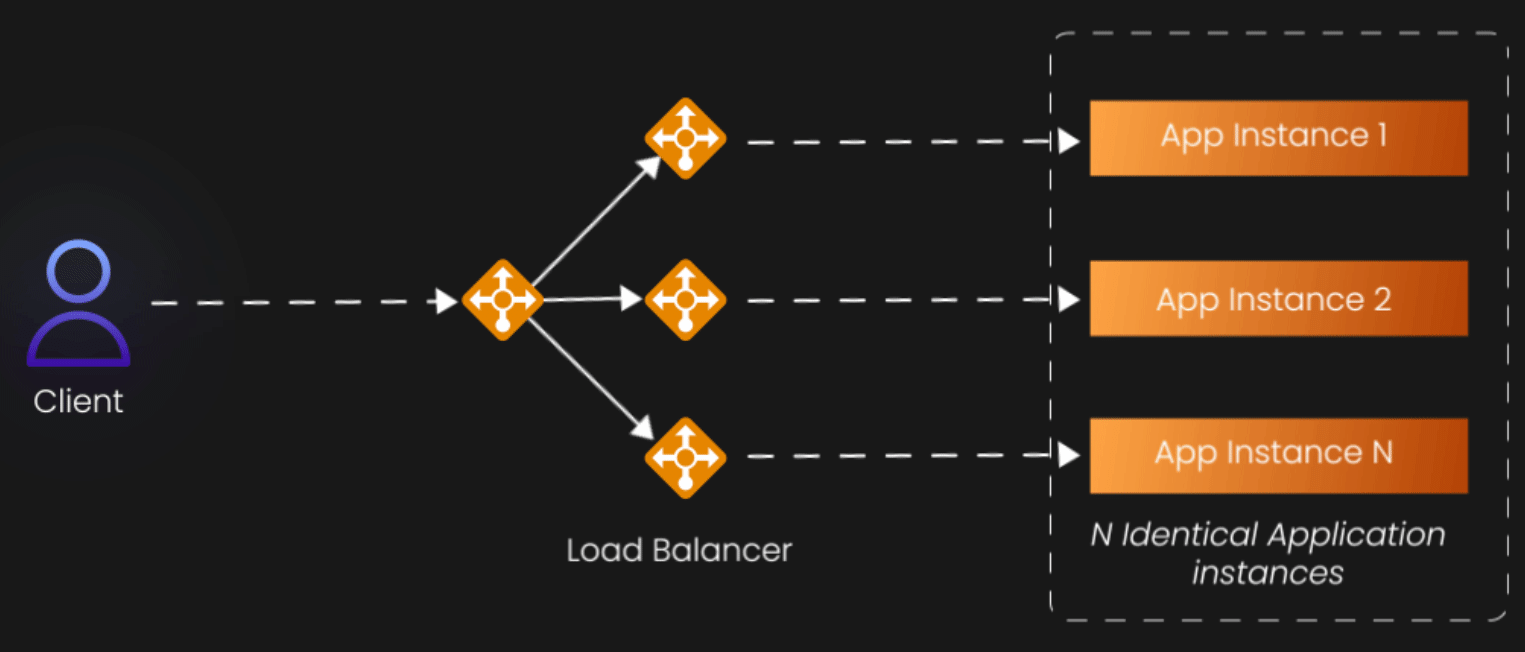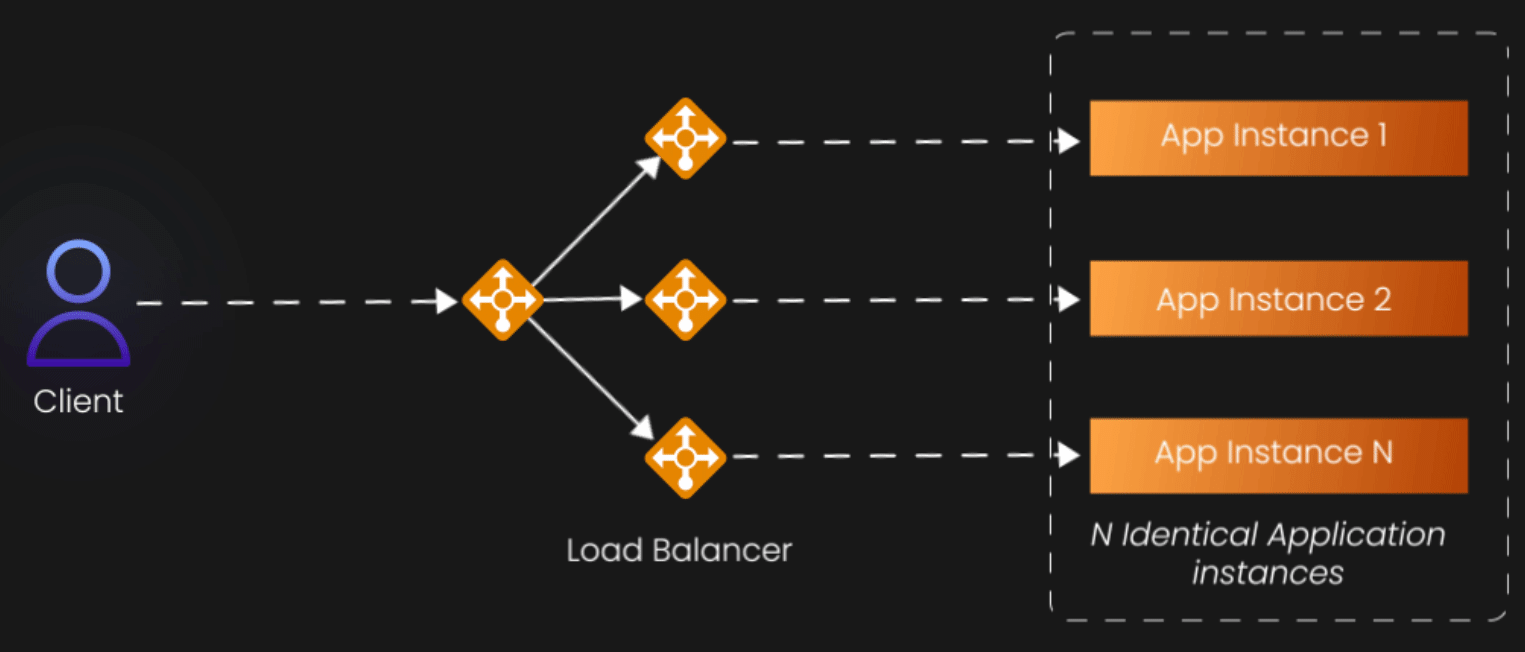
The X-Axis: When More is Simply More
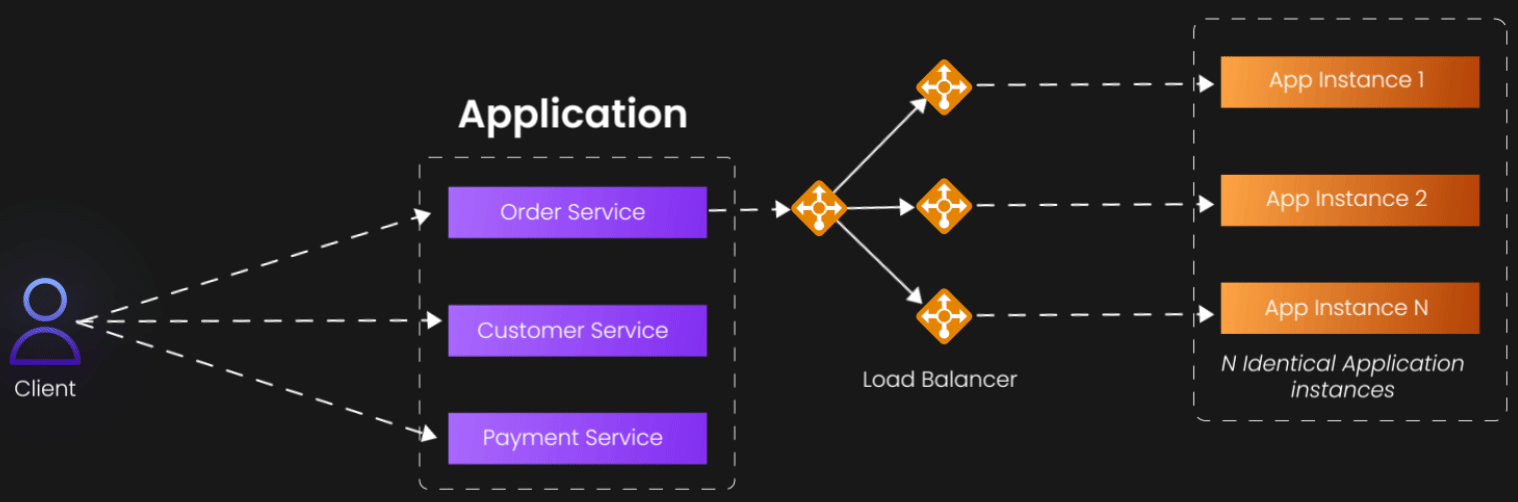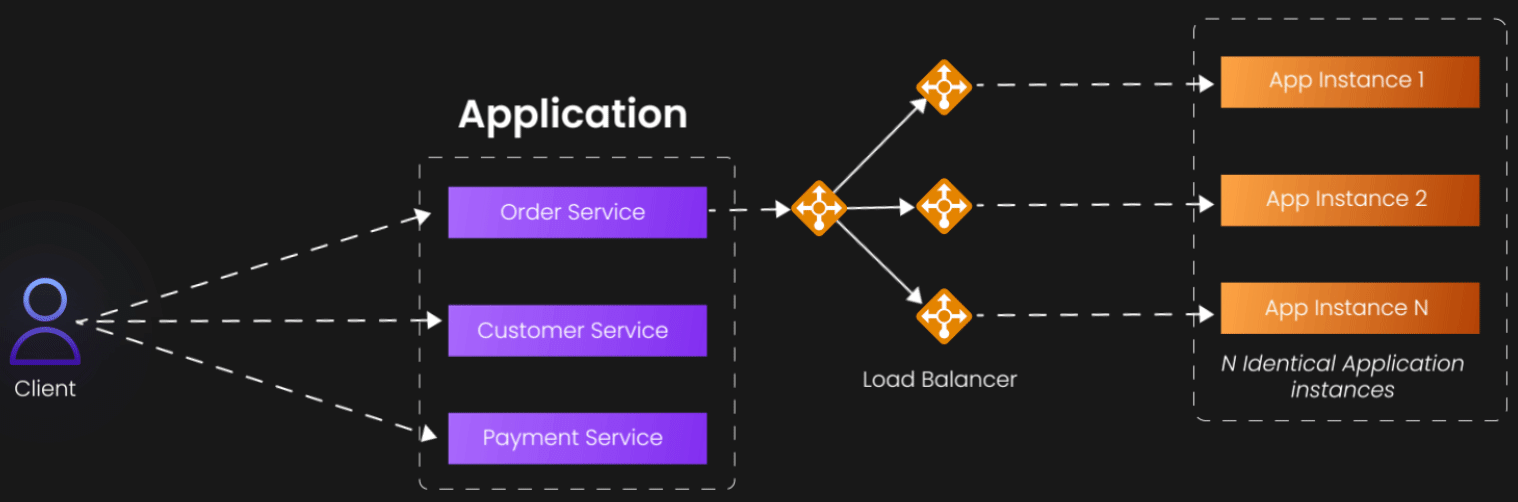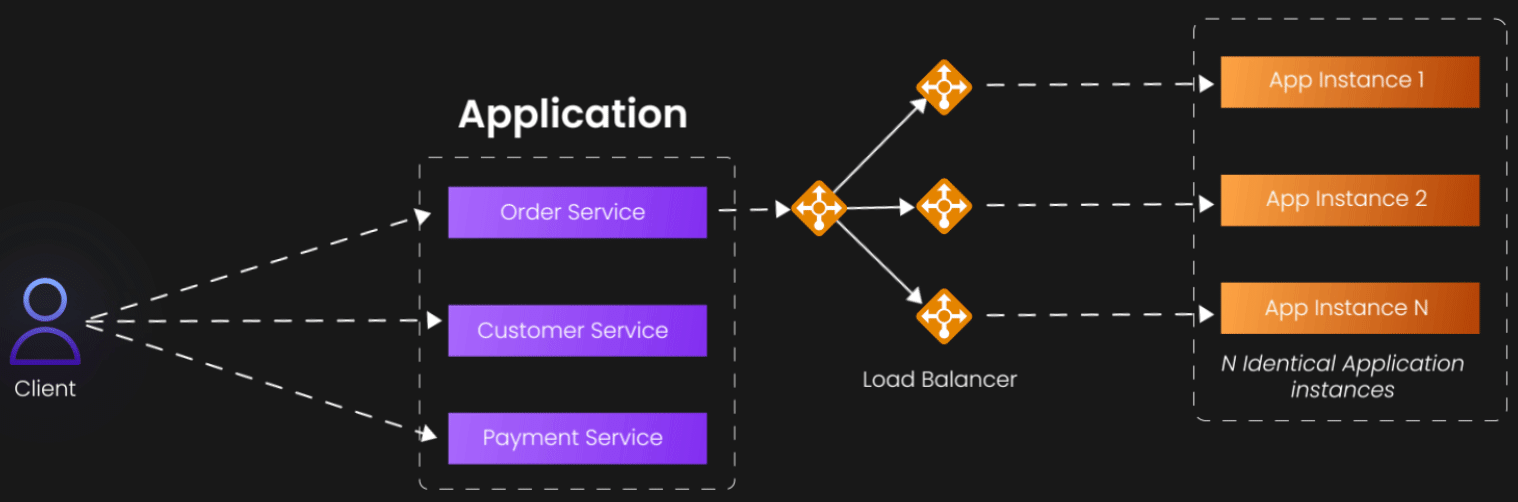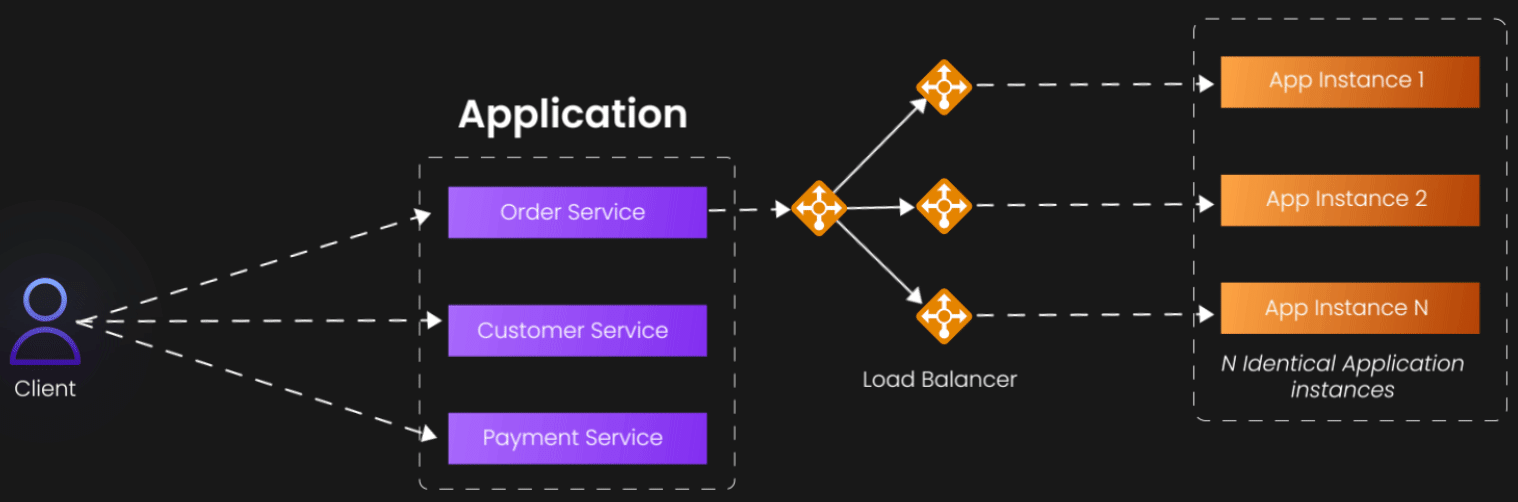
Let's start with the most intuitive dimension—the X-axis. This represents what most developers first reach for when their application starts struggling: horizontal scaling through replication. The concept is beautifully straightforward: if one server can handle 1,000 users, then two identical servers should handle 2,000 users, and ten servers should handle 10,000 users.
X-axis scaling involves running multiple identical instances of your application, typically behind a load balancer that distributes incoming requests across these instances. The load balancer acts as a traffic director, ensuring that no single instance becomes overwhelmed while others sit idle. This approach works because it transforms a single point of failure and bottleneck into a distributed system where the failure of any individual component doesn't bring down the entire service.
Consider a typical web application serving an e-commerce site. During normal business hours, a single server might comfortably handle the load. But during a flash sale or holiday shopping period, that same server becomes completely overwhelmed. By deploying multiple identical instances behind a load balancer, you can absorb those traffic spikes without degrading the user experience.
The beauty of X-axis scaling lies in its simplicity and broad applicability. It doesn't require you to fundamentally rethink your architecture or decompose your application into smaller pieces. You're essentially creating photocopies of your existing system and distributing the workload among them. This makes it an excellent first step for many scaling challenges, particularly for stateless applications where each request can be handled independently.
However, X-axis scaling has its limitations. While it can handle increased traffic, it doesn't address other types of scaling challenges. If your database becomes the bottleneck, adding more application servers won't help. If your codebase becomes unwieldy and difficult to maintain, more instances of that unwieldy codebase won't solve the problem. X-axis scaling is powerful, but it's not a universal solution.
The Y-Axis: Divide and Conquer
The Y-axis represents a more sophisticated approach to scaling: functional decomposition. Instead of creating identical copies of your entire application, Y-axis scaling involves breaking your application into smaller, specialized services, each responsible for a specific business function. This is the architectural pattern we now commonly call microservices.
In practical terms, your monolithic e-commerce application might be decomposed into separate services for user authentication, product catalog management, shopping cart functionality, order processing, and payment handling. Each service becomes a focused, self-contained unit with its own database, its own development team, and its own deployment schedule.
This functional decomposition offers several compelling advantages. Different services can be scaled independently based on their specific load patterns—your product catalog might need to handle thousands of read operations per second during peak browsing times, while your payment service might have a much lower but more critical transaction volume. Development teams can work on different services simultaneously without stepping on each other's toes, accelerating feature development and reducing coordination overhead.
Y-axis scaling also provides better fault isolation. When your monolithic application fails, everything fails together. When a microservice fails, it only affects its specific functionality, leaving the rest of the system operational. Your users might not be able to add items to their cart during a shopping cart service outage, but they can still browse products and view their order history.
The relationship between Y-axis scaling and microservices is more than coincidental—microservices architecture is essentially the systematic application of Y-axis scaling principles. This is why understanding the Scale Cube provides such valuable context for microservices discussions. It helps you see microservices not as a trendy architectural style, but as a specific solution to specific scaling challenges.
However, Y-axis scaling introduces its own complexity. Service boundaries must be carefully designed to minimize inter-service communication. You need to solve problems like distributed transactions, service discovery, and network partitions. The operational complexity of managing many small services can be significantly higher than managing a single large application, especially for smaller teams.
The Z-Axis: Splitting by Data
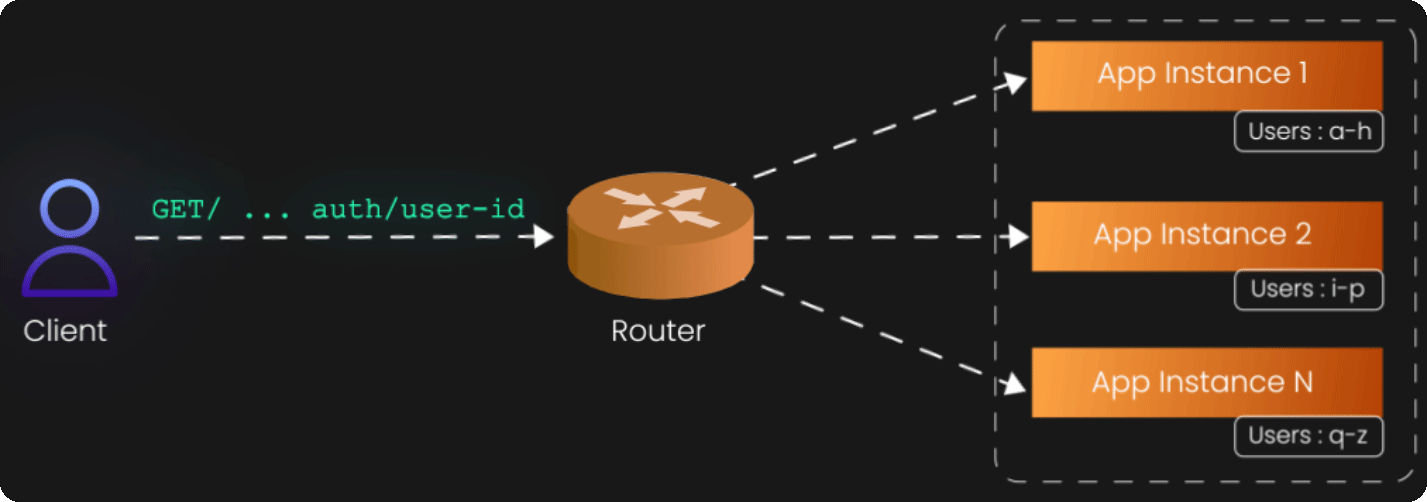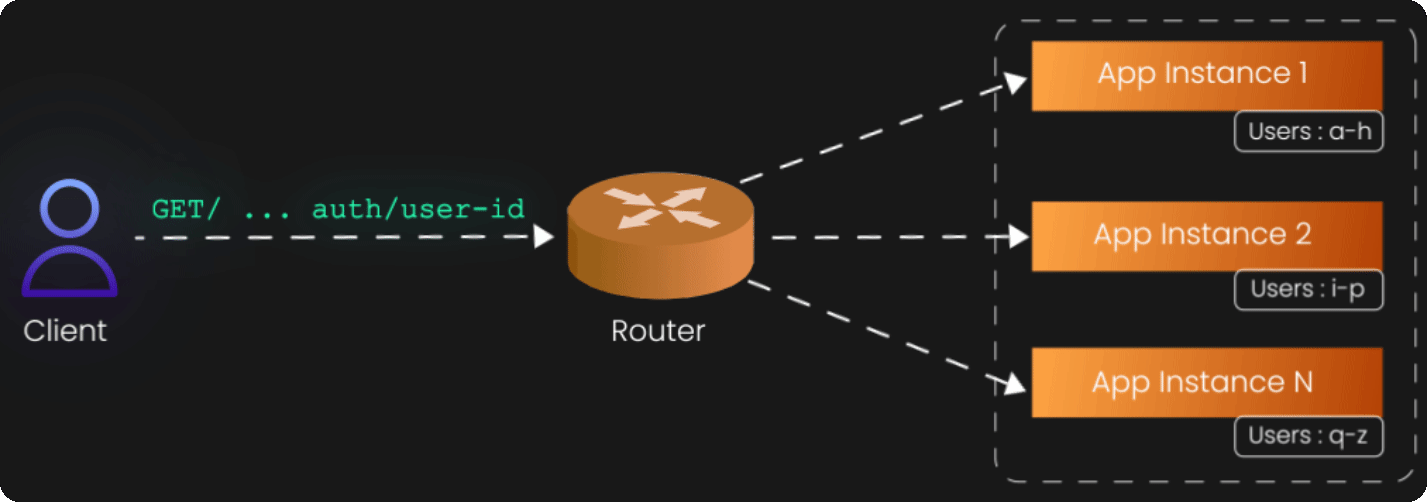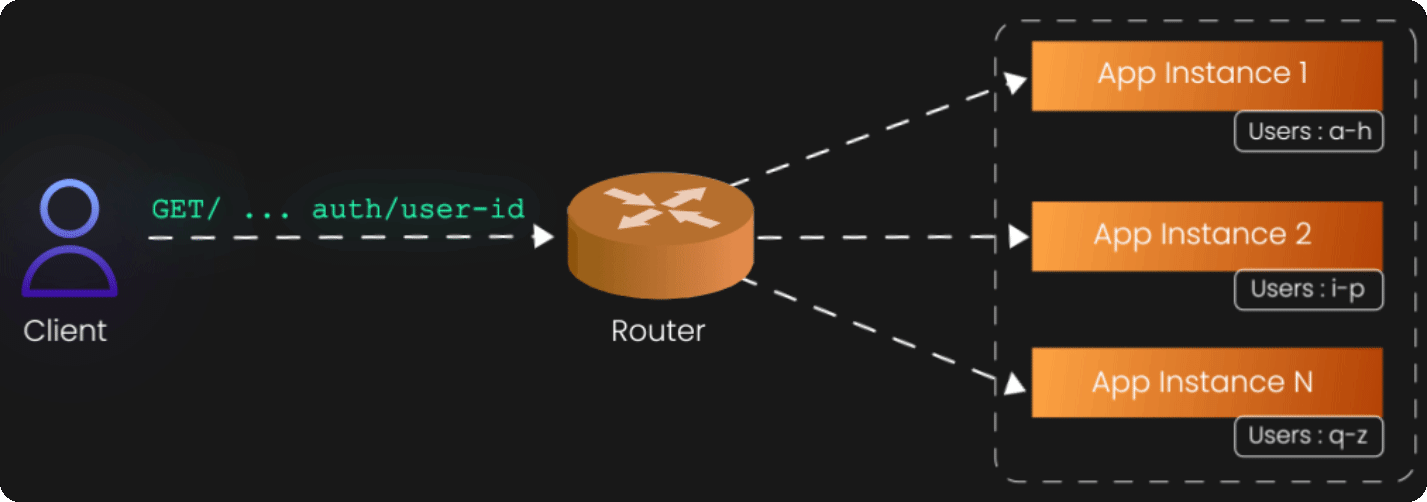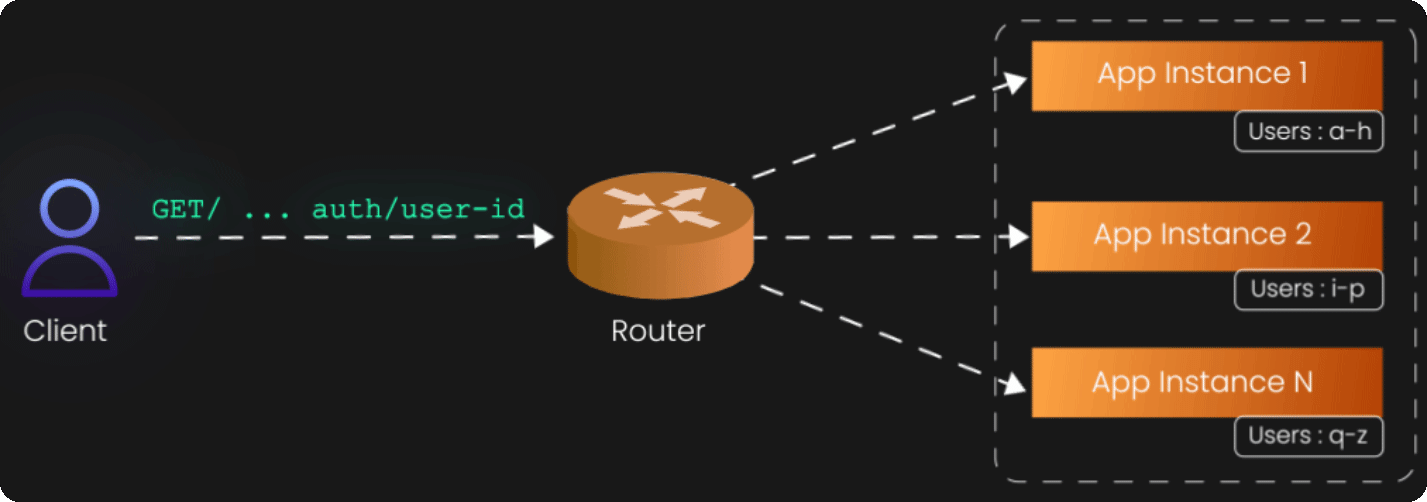
The Z-axis represents perhaps the most sophisticated scaling approach: data partitioning or sharding. While X-axis scaling distributes identical requests across identical instances, and Y-axis scaling distributes different functions across specialized services, Z-axis scaling distributes different subsets of data across different instances.
Z-axis scaling recognizes that not all data is created equal. Some users generate more load than others, some geographic regions have different usage patterns, and some customers have different performance requirements. Rather than treating all data identically, Z-axis scaling routes requests to different instances based on attributes of the data or the request itself.
Consider a social media platform with millions of users. A naive approach might be to replicate the entire user database across multiple servers (X-axis scaling). But this becomes increasingly expensive and complex as the database grows. Z-axis scaling offers a more elegant solution: partition users by geographic region, user ID ranges, or account type. European users might be served by servers physically located in Europe, while American users are served by servers in the United States. Premium users might be served by high-performance instances, while free users are served by more modest infrastructure.
The routing logic for Z-axis scaling typically lives in a layer above the application instances—a smart load balancer or routing service that examines incoming requests and directs them to the appropriate partition. This router becomes a critical component of your architecture, as it must understand the partitioning scheme and route requests correctly.
Z-axis scaling offers several powerful advantages. It can significantly improve performance by ensuring that data is physically closer to users and that high-value customers get dedicated resources. It also enables you to tailor your infrastructure to different usage patterns—you might use different database configurations for analytical workloads versus transactional workloads, or different security configurations for different customer tiers.
However, Z-axis scaling introduces significant complexity. The partitioning scheme must be carefully designed to avoid hotspots where some partitions become overloaded while others remain underutilized. Cross-partition operations become expensive and complex—imagine trying to generate a report that requires data from multiple geographic regions or customer tiers. The routing logic must be highly available and performant, as it becomes a critical path for all requests.
Why This Matters for System Design
For those preparing for system design interviews, the Scale Cube provides a structured vocabulary for discussing scalability trade-offs. Instead of jumping immediately to specific technologies, you can use the Scale Cube to demonstrate systematic thinking about the problem space.
When asked to design a system that can handle millions of users, you can walk through each axis of the Scale Cube, explaining when and why you might apply each approach. This shows that you understand not just the mechanics of scaling, but the strategic thinking that goes into choosing the right scaling approach for the right situation.
The Scale Cube also helps you avoid the trap of over-engineering solutions.
Not every application needs microservices (Y-axis scaling). Not every system needs complex data partitioning (Z-axis scaling). By understanding the specific problems each axis addresses, you can make more informed decisions about when the complexity of advanced scaling approaches is justified.
The Path Forward
The Scale Cube isn't a prescription for how to scale your application—it's a framework for thinking about scalability in a structured way.
Your specific context, constraints, and requirements will ultimately determine which approaches make sense for your situation.
Start by understanding where your current bottlenecks lie. Are you CPU-bound, memory-bound, or I/O-bound? Are you struggling with traffic volume, feature complexity, or data diversity? Use the Scale Cube to map these challenges to potential solutions, but remember that the simplest solution that addresses your actual constraints is usually the right one.
Most importantly, remember that scalability is a journey, not a destination. The Scale Cube provides a map for that journey, helping you navigate from where you are to where you need to be, one axis at a time.