
How Amazon S3 Promises to Never Lose Your Data
The Engineering Behind 11 Nines

Amazon S3 makes an extraordinary promise: 99.999999999% durability. That's eleven nines, meaning if you stored 10,000 files in S3, you might statistically lose one file every 10 million years.
Companies store exabytes of data in S3, Netflix's video catalog, NASA's satellite imagery, millions of corporate backups. At that scale, achieving this level of reliability requires sophisticated engineering.
How does a system handling trillions of objects across millions of customers achieve this level of reliability? The answer reveals fundamental principles about building resilient systems that apply far beyond cloud storage.
Understanding Durability vs. Availability
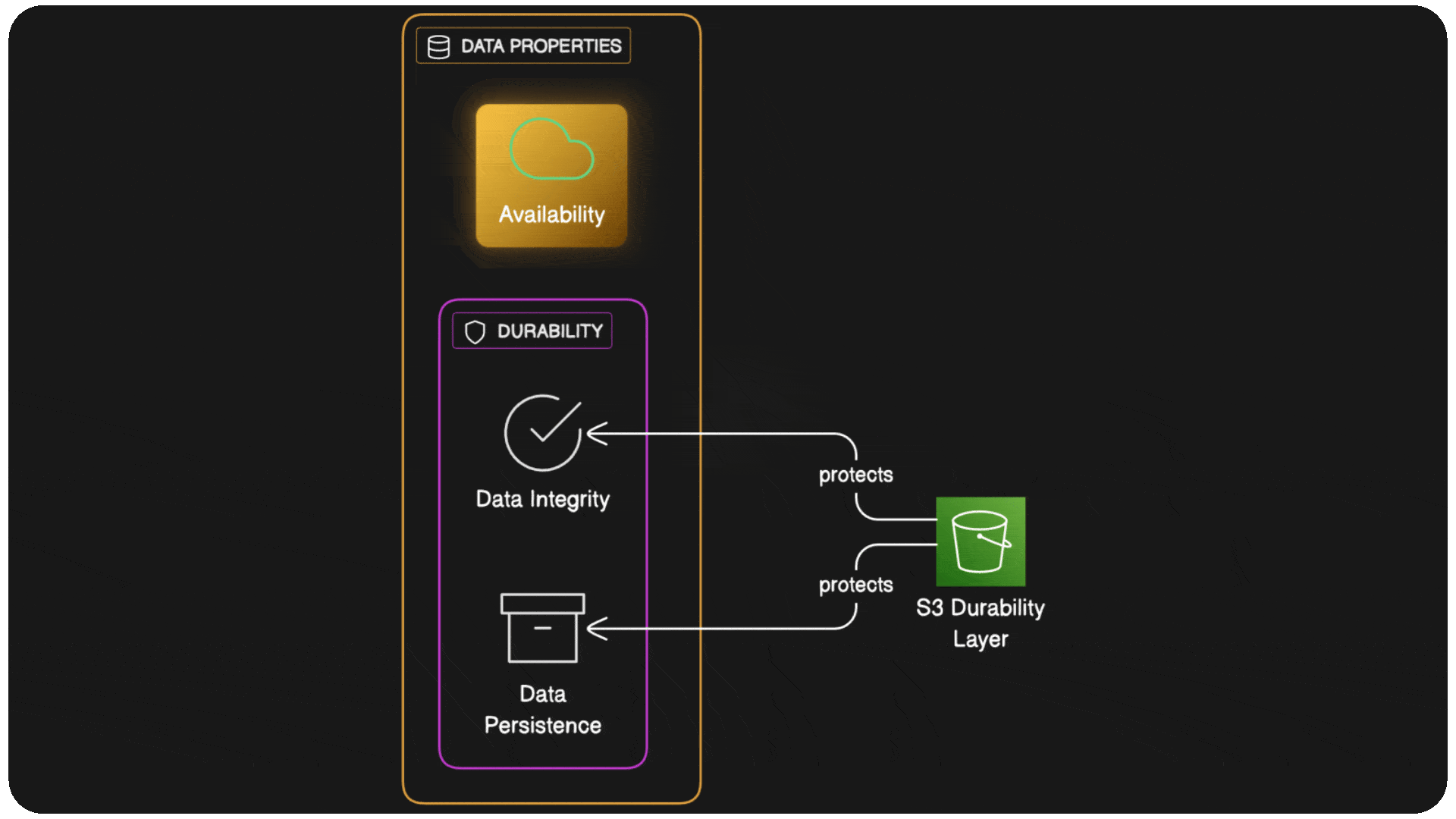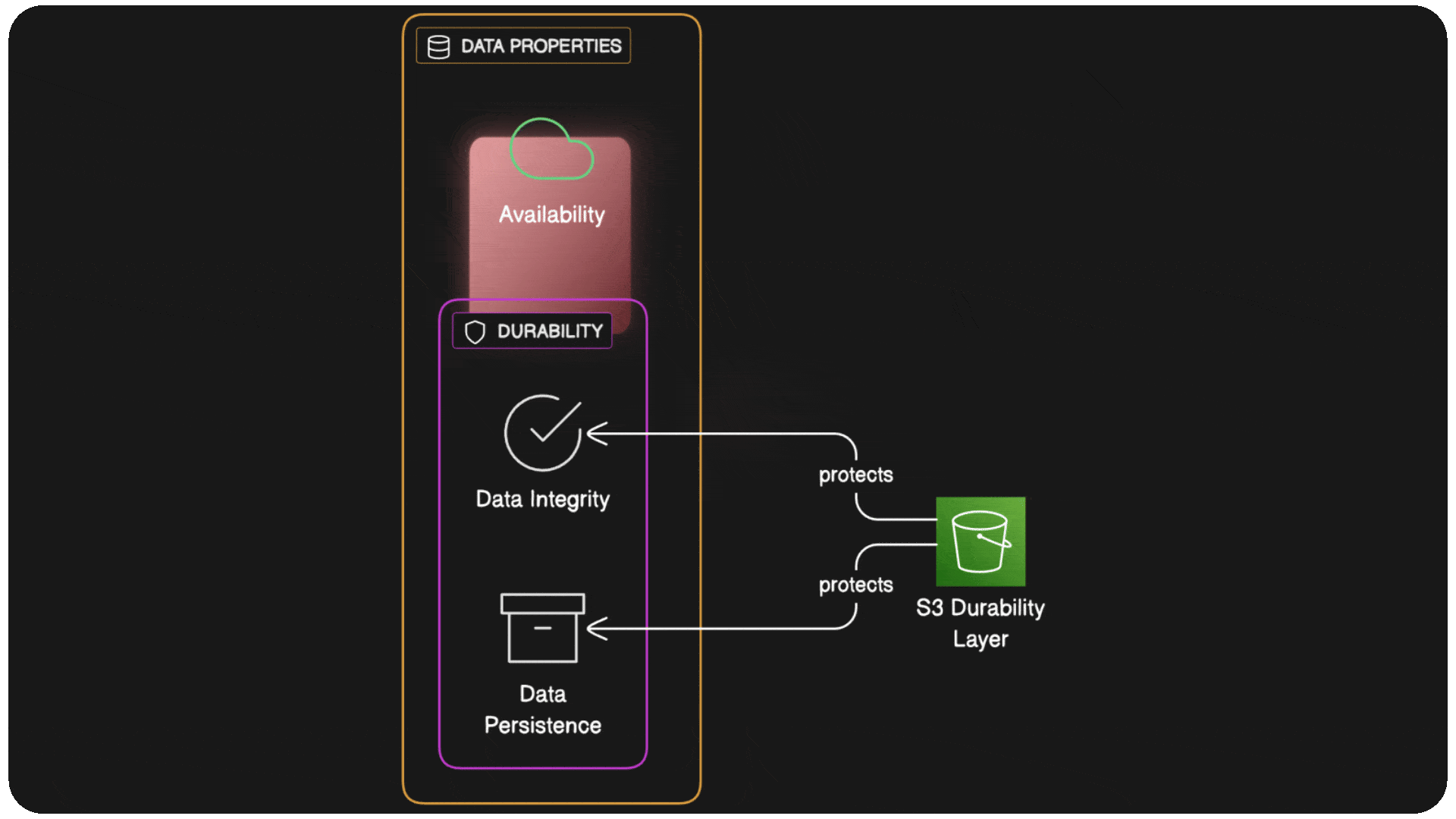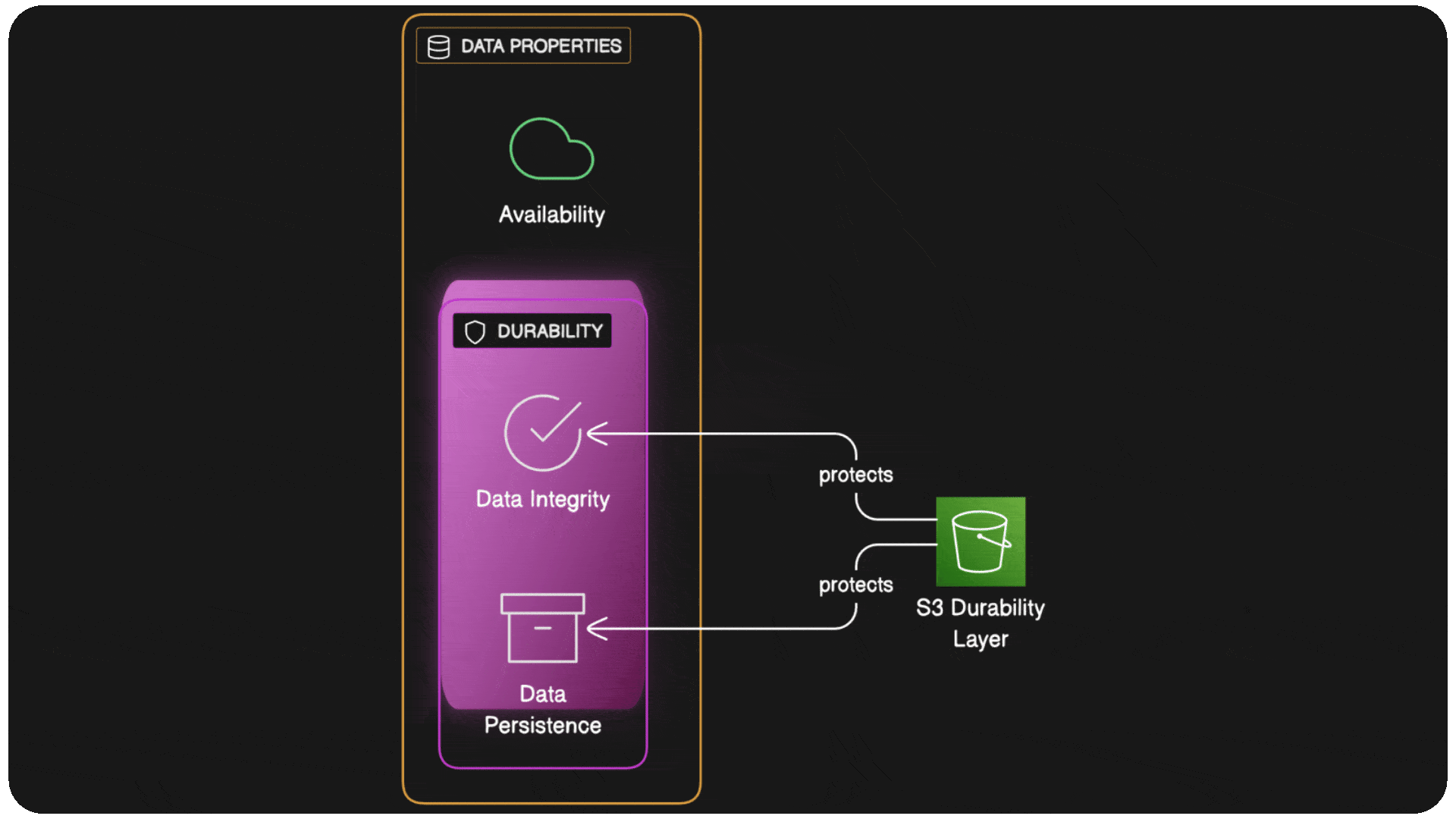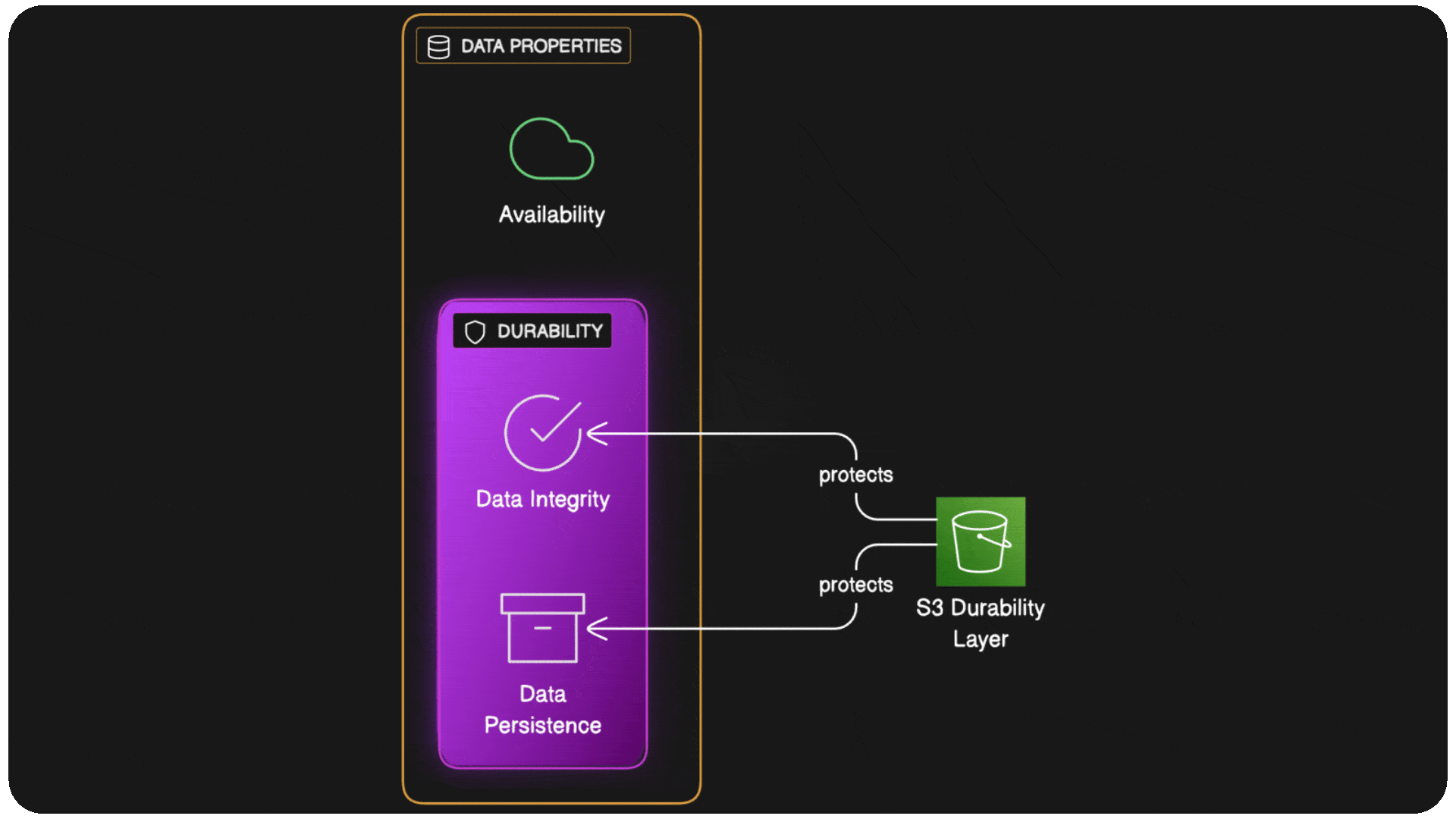
Before diving into S3's architecture, we need to clarify what durability actually means, because it's often confused with availability, and the distinction is crucial.
Availability is about accessing your data when you need it. If S3 is unavailable, you might get error messages or timeouts, but your data still exists somewhere in Amazon's infrastructure. Availability problems are inconvenient and can cost money, but they're typically temporary.
Durability is about ensuring your data never disappears or becomes corrupted. If S3 has a durability failure, your data is gone forever, no amount of waiting or retrying will bring it back. Durability failures are catastrophic and permanent.
This distinction shapes every architectural decision in S3. While availability problems can be solved with redundancy and failover mechanisms, durability requires a fundamentally different approach to how data is stored, protected, and maintained over time.
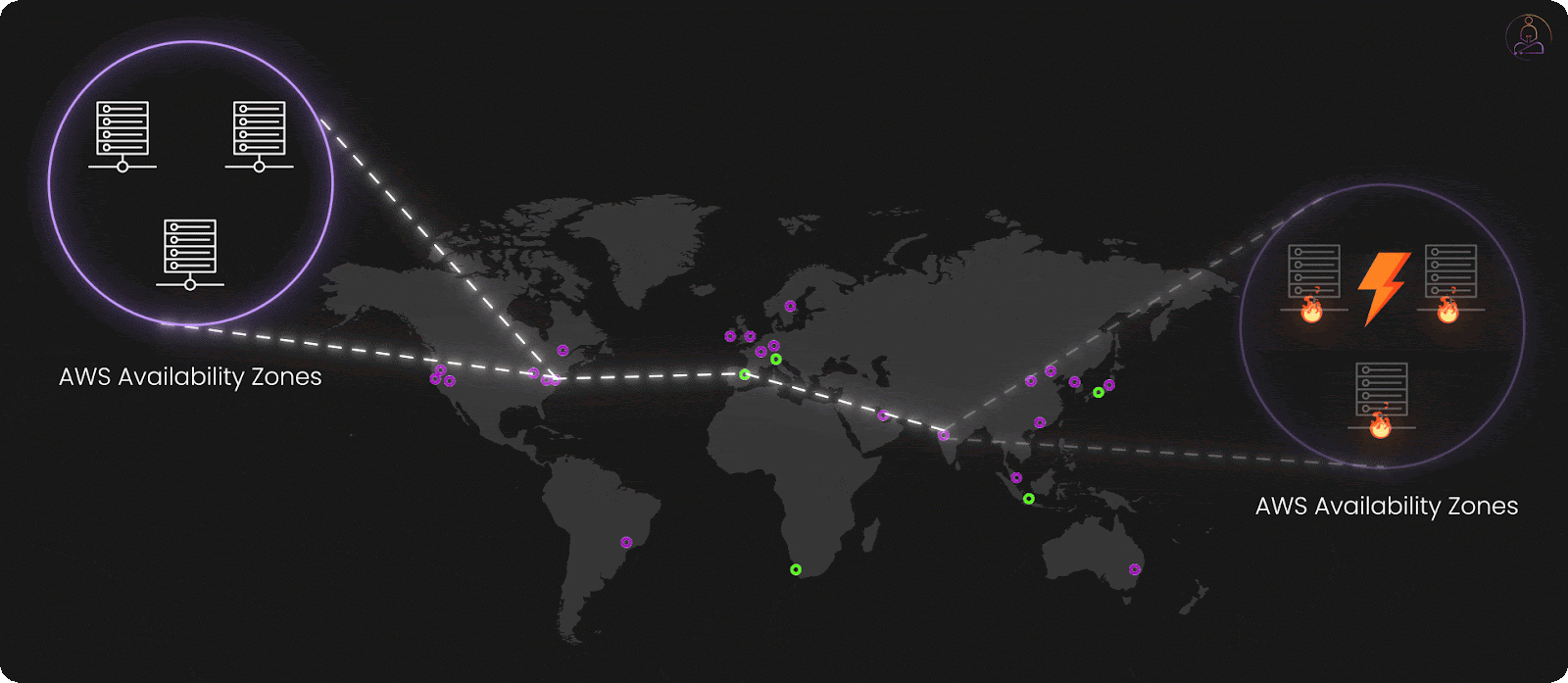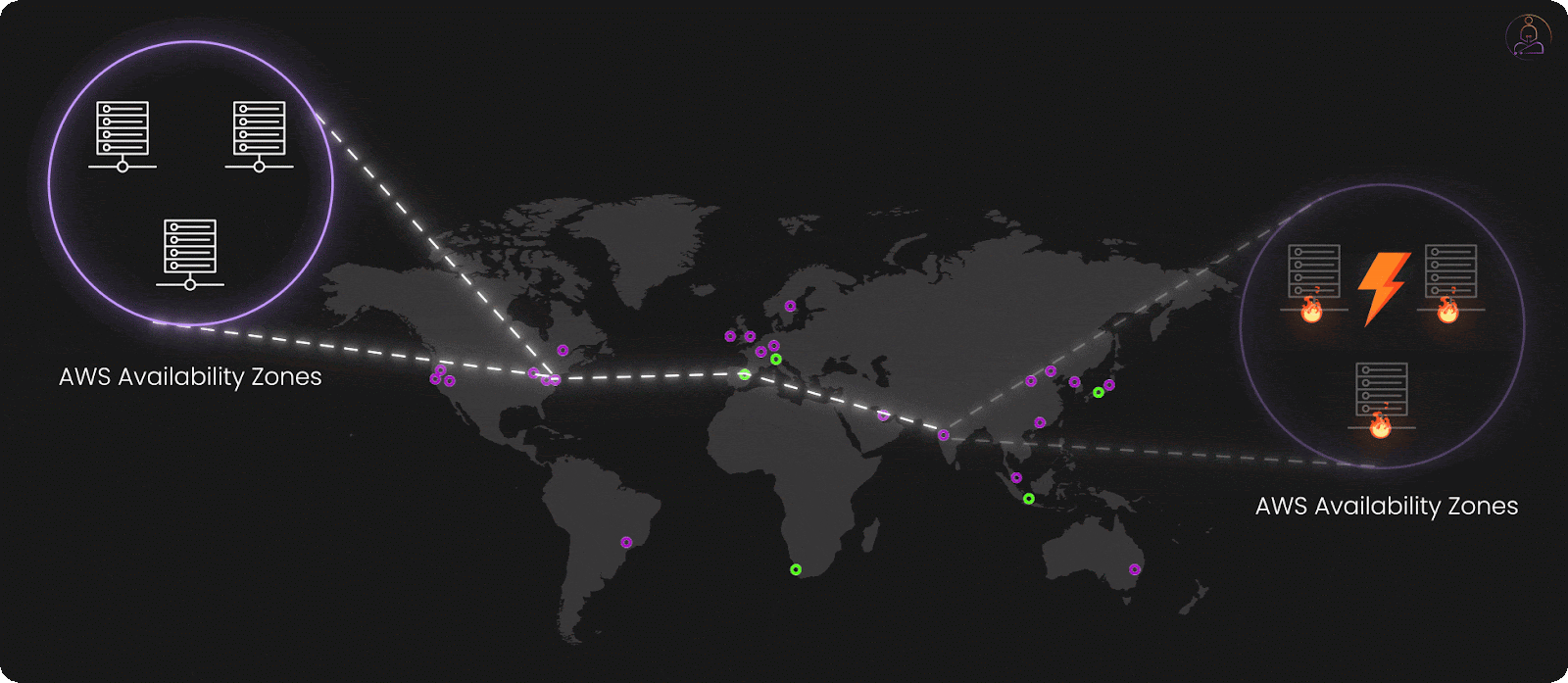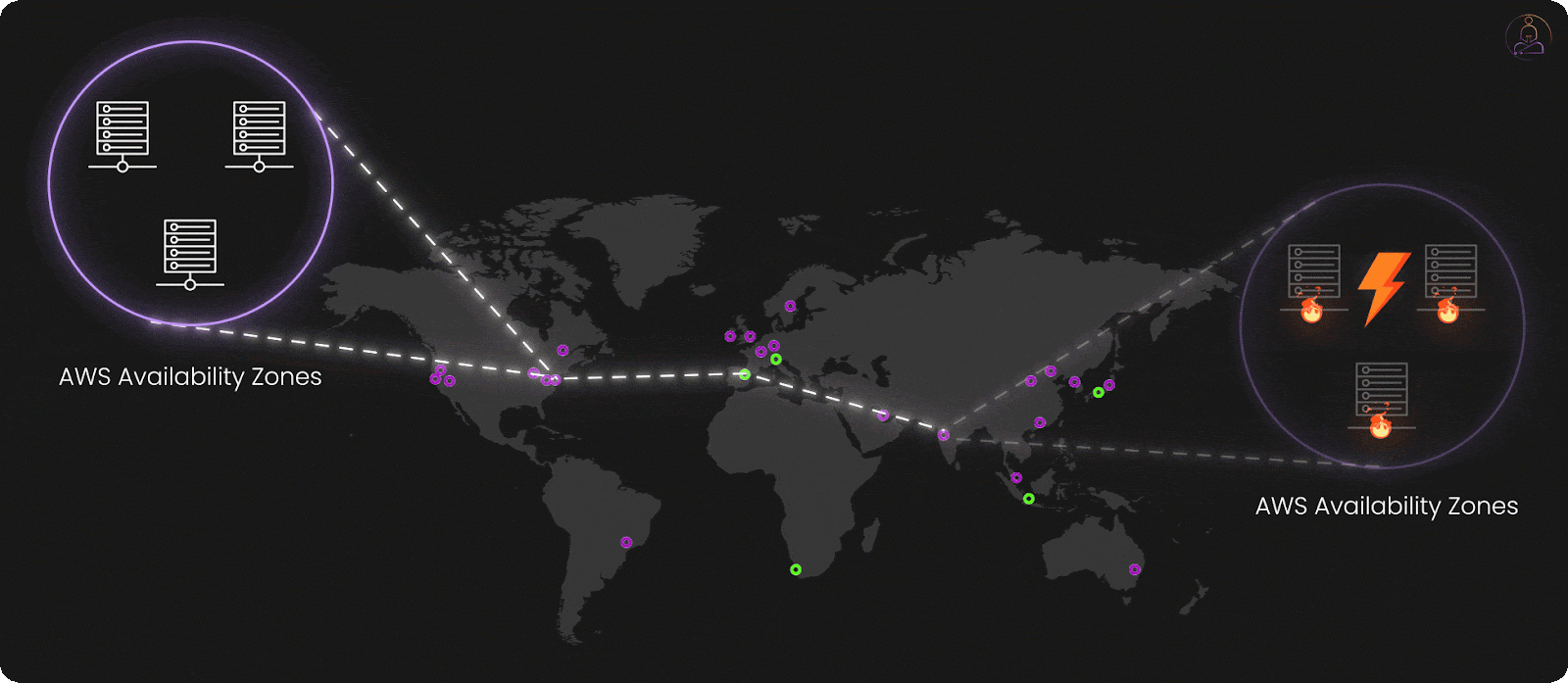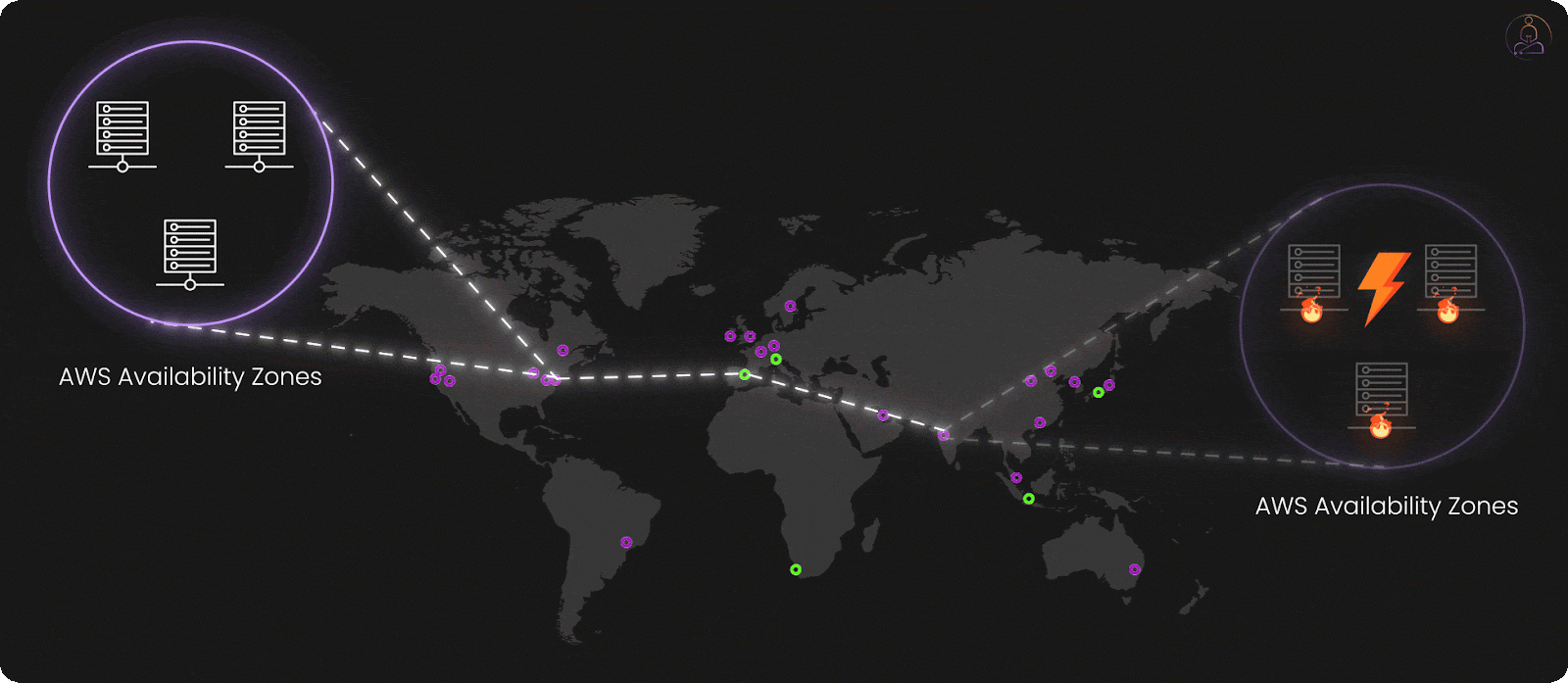
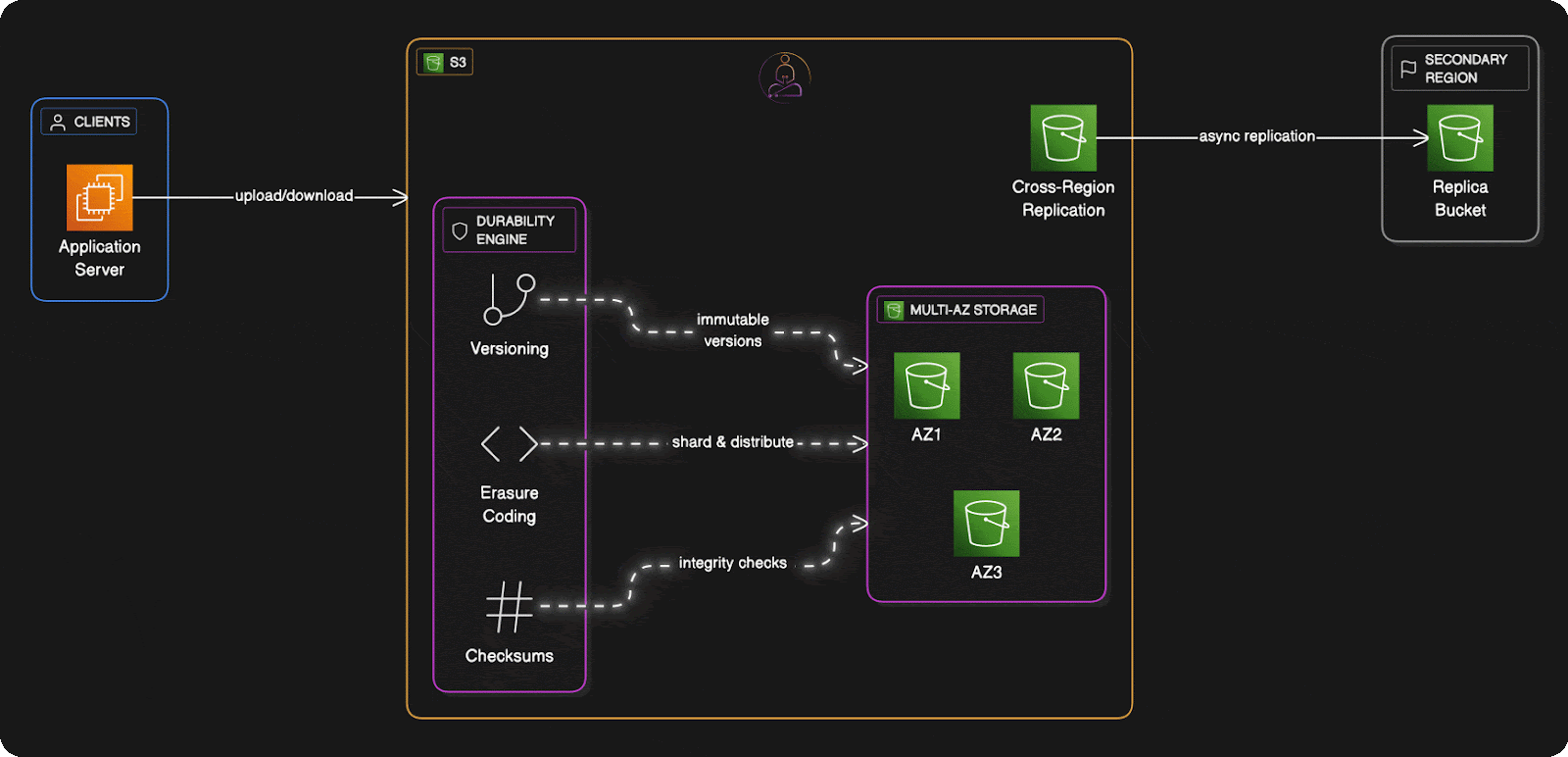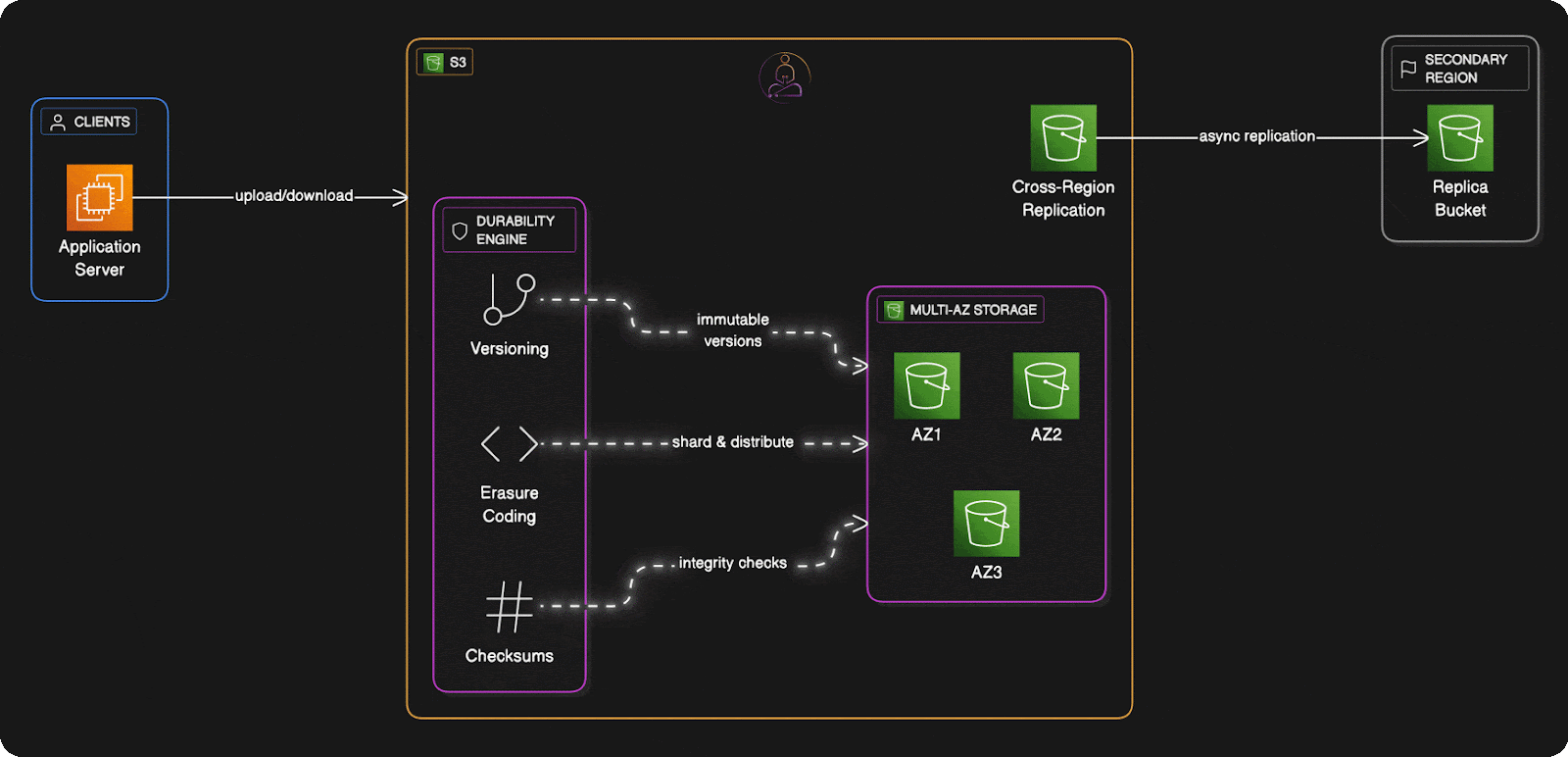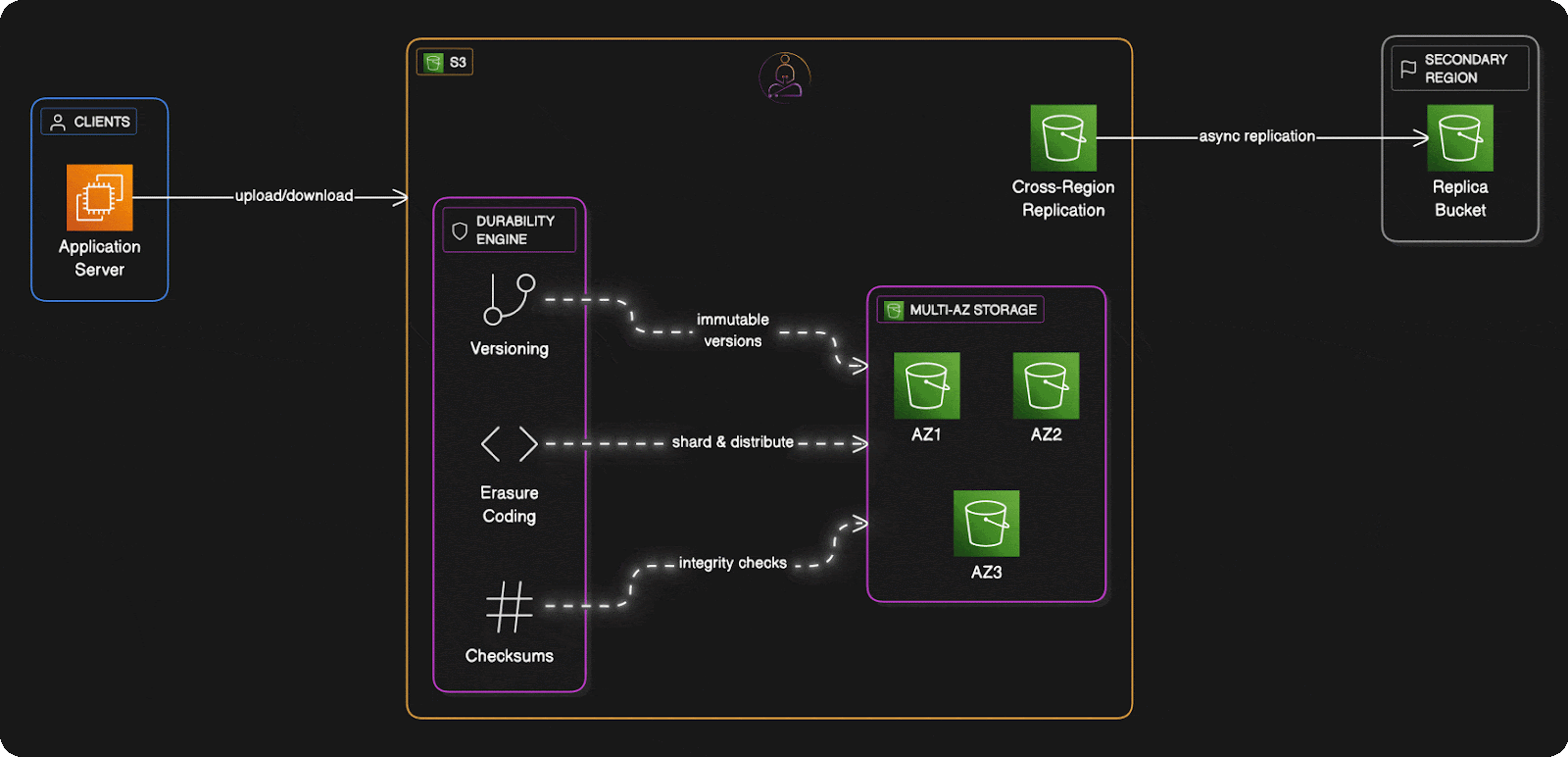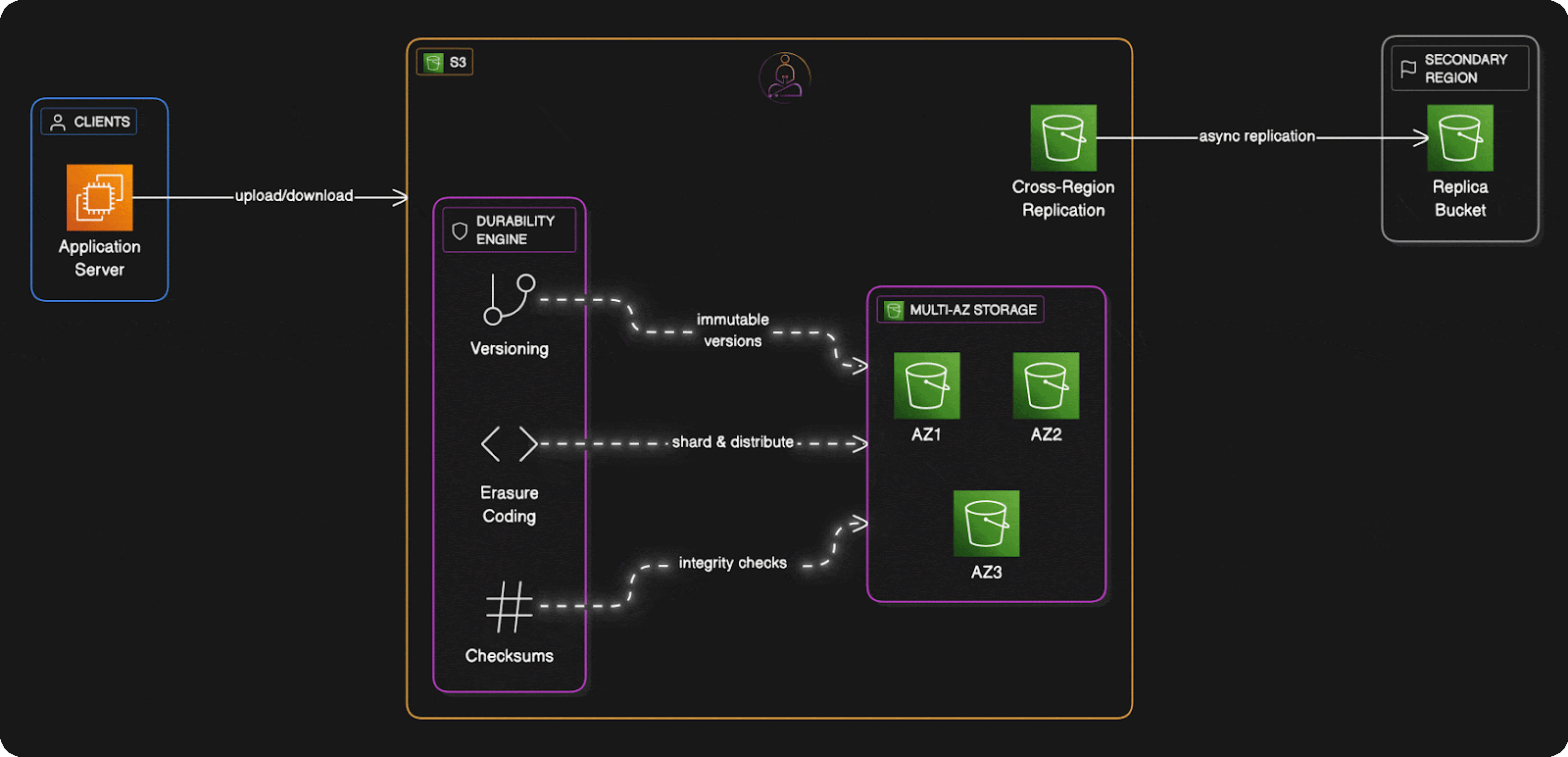
S3's first principle is simple: don't put all your eggs in one basket. At the massive scale AWS operates, hard drives fail constantly, not occasionally, but every single day across their infrastructure.Instead of fighting this reality, S3 embraces it by spreading your data across multiple physical devices from the moment it arrives.
When you upload a file, S3 doesn't just save it to one disk and call it done. It immediately replicates that data across different servers, different storage racks, and different availability zones.
Availability zones are essentially separate data centers, each with independent power systems, network connections, and cooling infrastructure. They're often located miles apart within a region. This means that even if an entire data center loses power or faces a natural disaster, your data remains intact and accessible from other zones.
But S3 goes beyond simple replication with a technique called erasure coding: a more sophisticated approach borrowed from telecommunications and refined for cloud-scale storage.
Erasure Coding: The Mathematics of Resilience
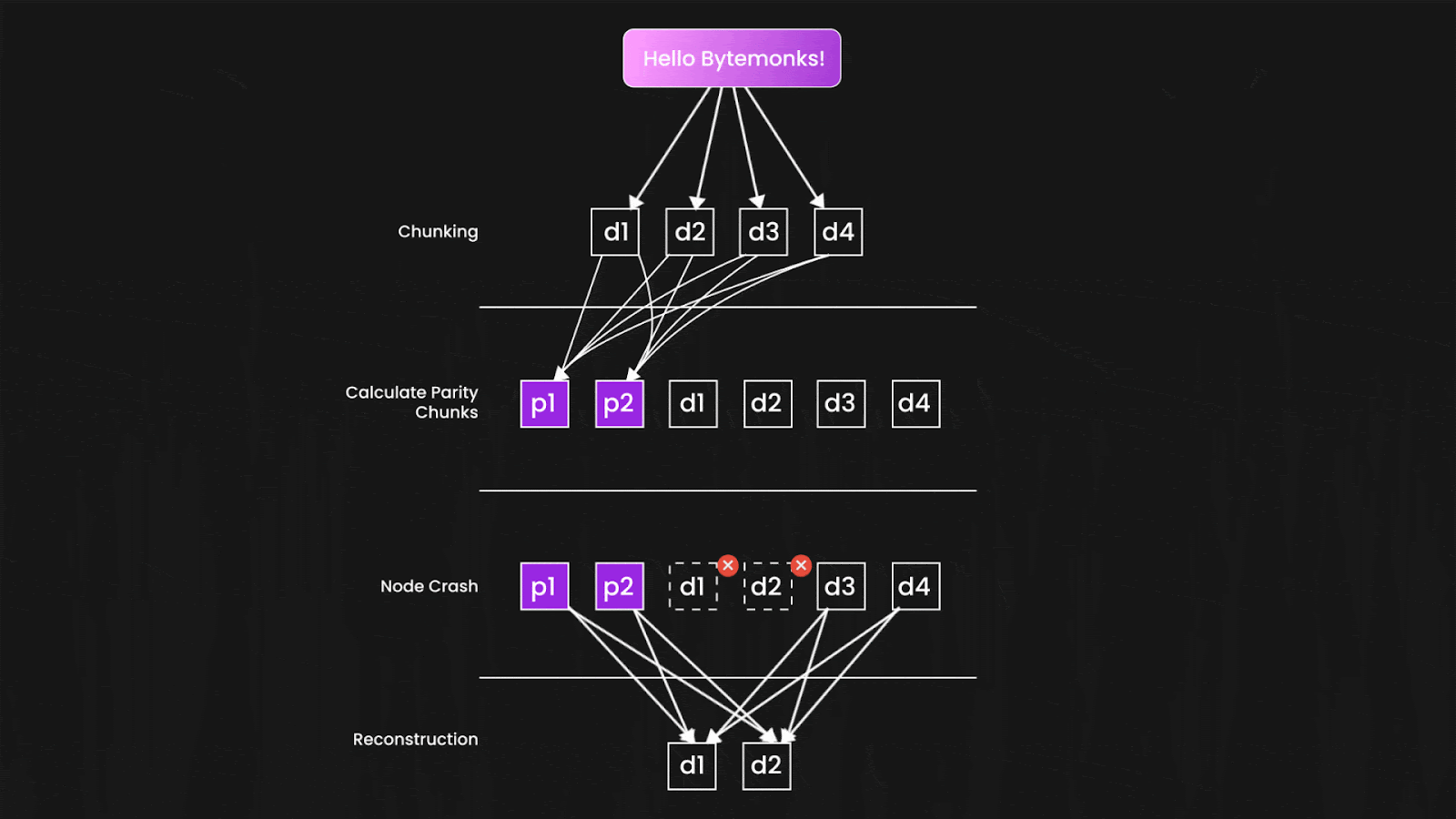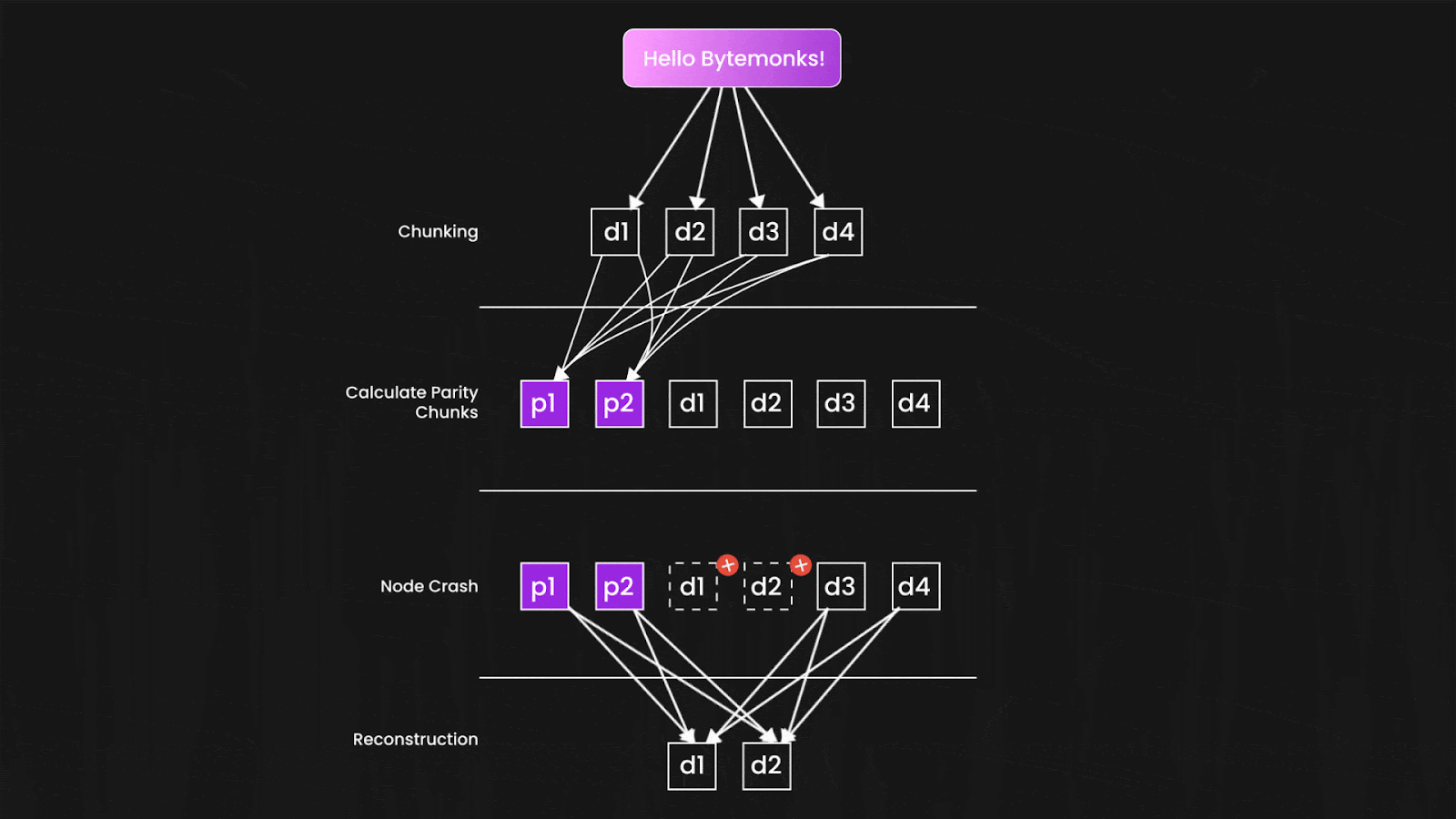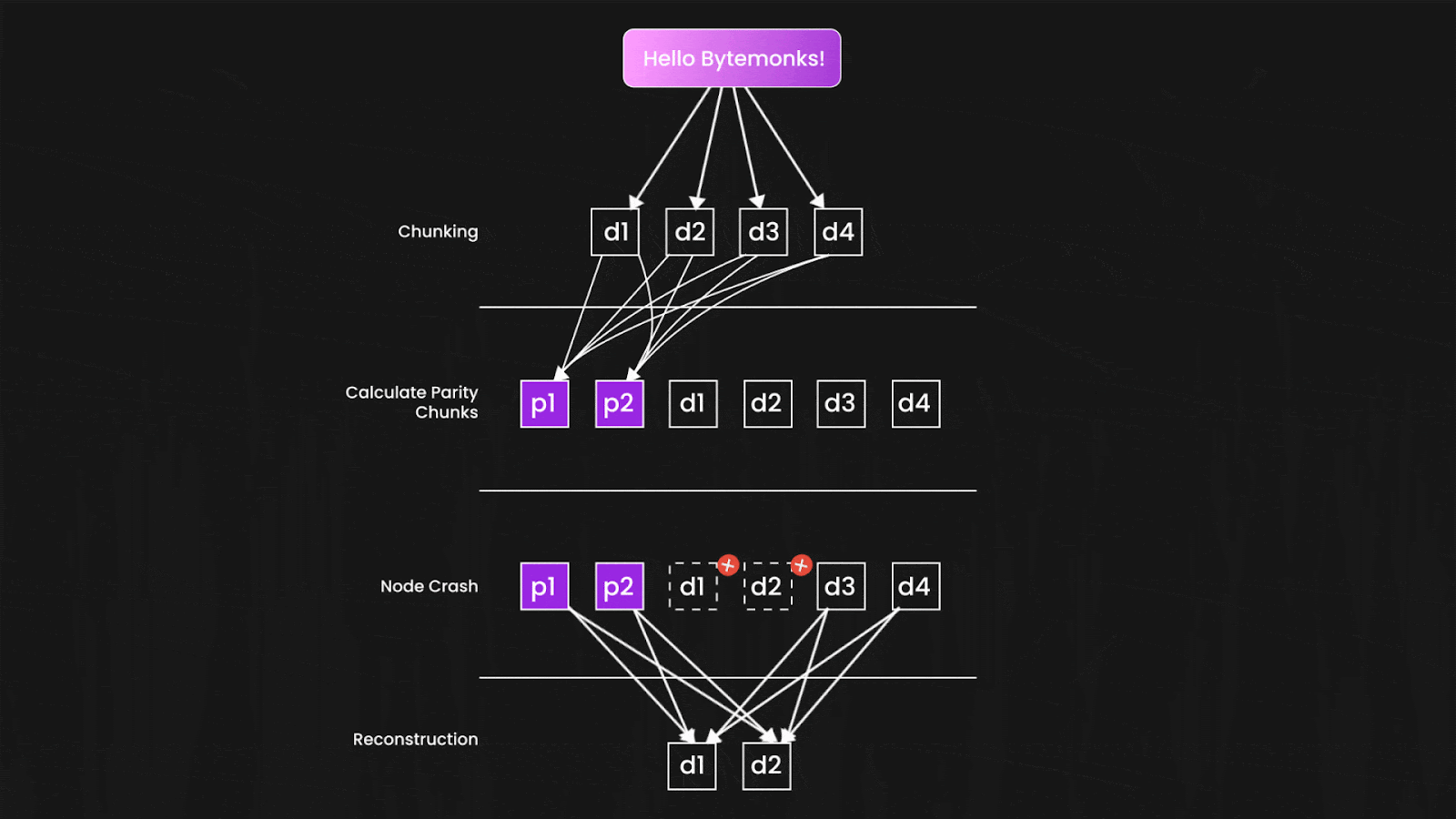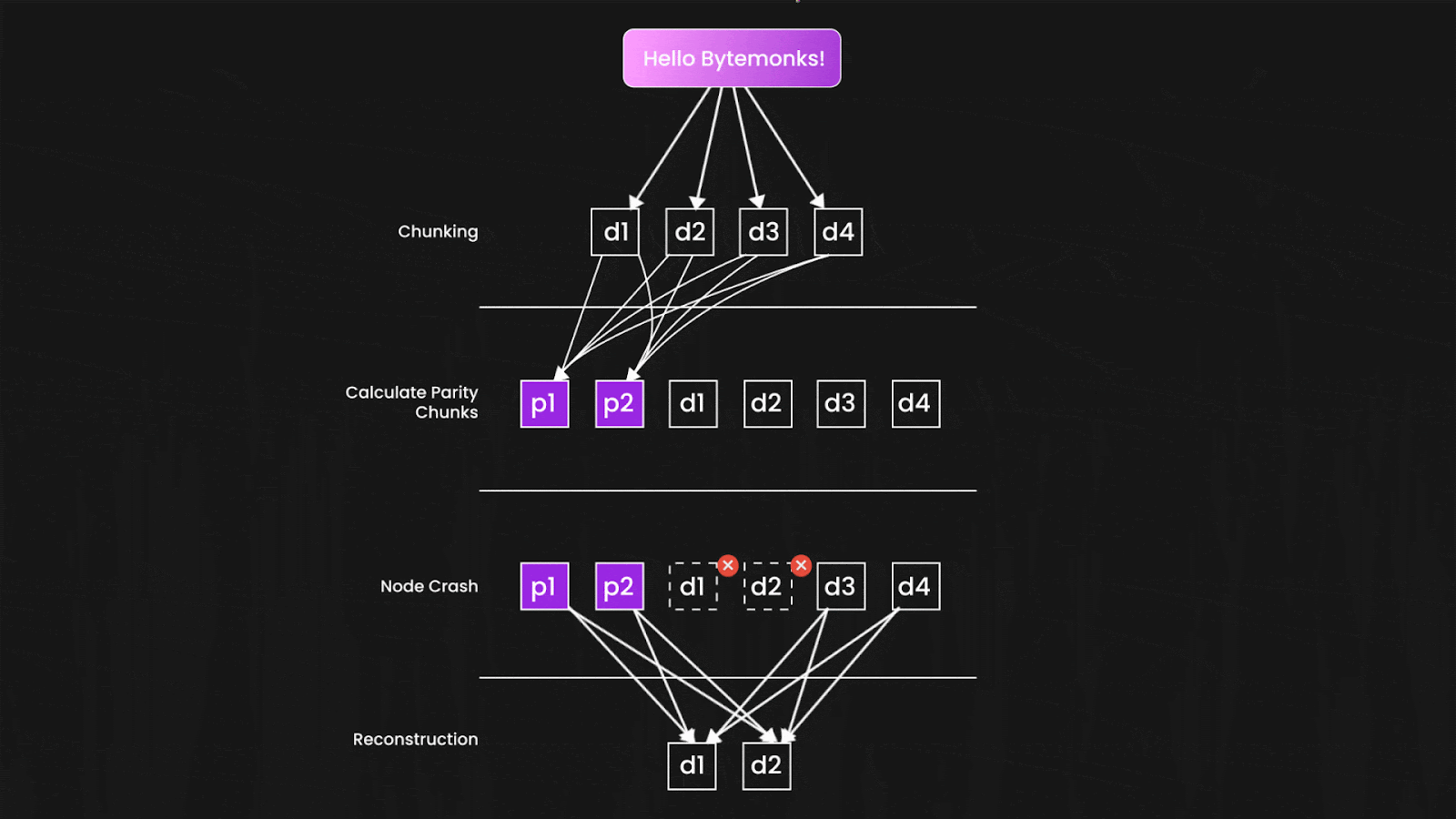
Instead of making exact copies of your data, S3 Erasure Coding breaks each object into smaller pieces called data shards, then generates additional parity shards using mathematical algorithms.
Here's the clever part: you only need a subset of these shards to reconstruct your original file. If S3 creates 10 shards total and needs only 6 to rebuild your data, then 4 shards can disappear completely without any data loss.
This approach is far more efficient than simple duplication. Instead of storing 3 complete copies of your data (requiring 3x the storage space), erasure coding might provide the same level of protection using only 1.5x the space, while actually providing better fault tolerance.
The shards are distributed not just across different disks, but across different servers, racks, and even data centers. The mathematical probability that enough shards would fail simultaneously to cause data loss becomes astronomically small—which is how S3 can confidently promise those eleven nines.
Proactive Health Monitoring and Recovery
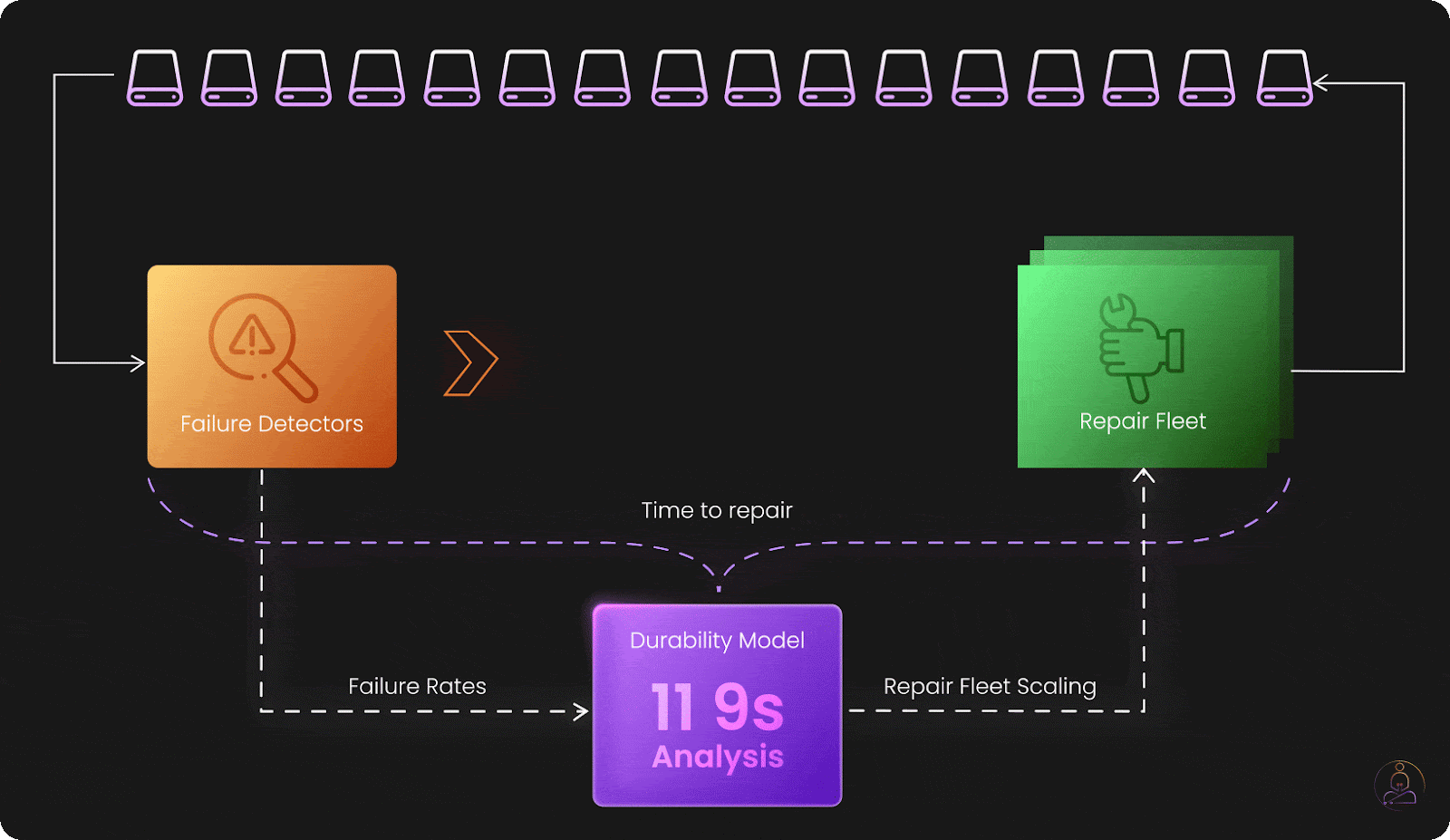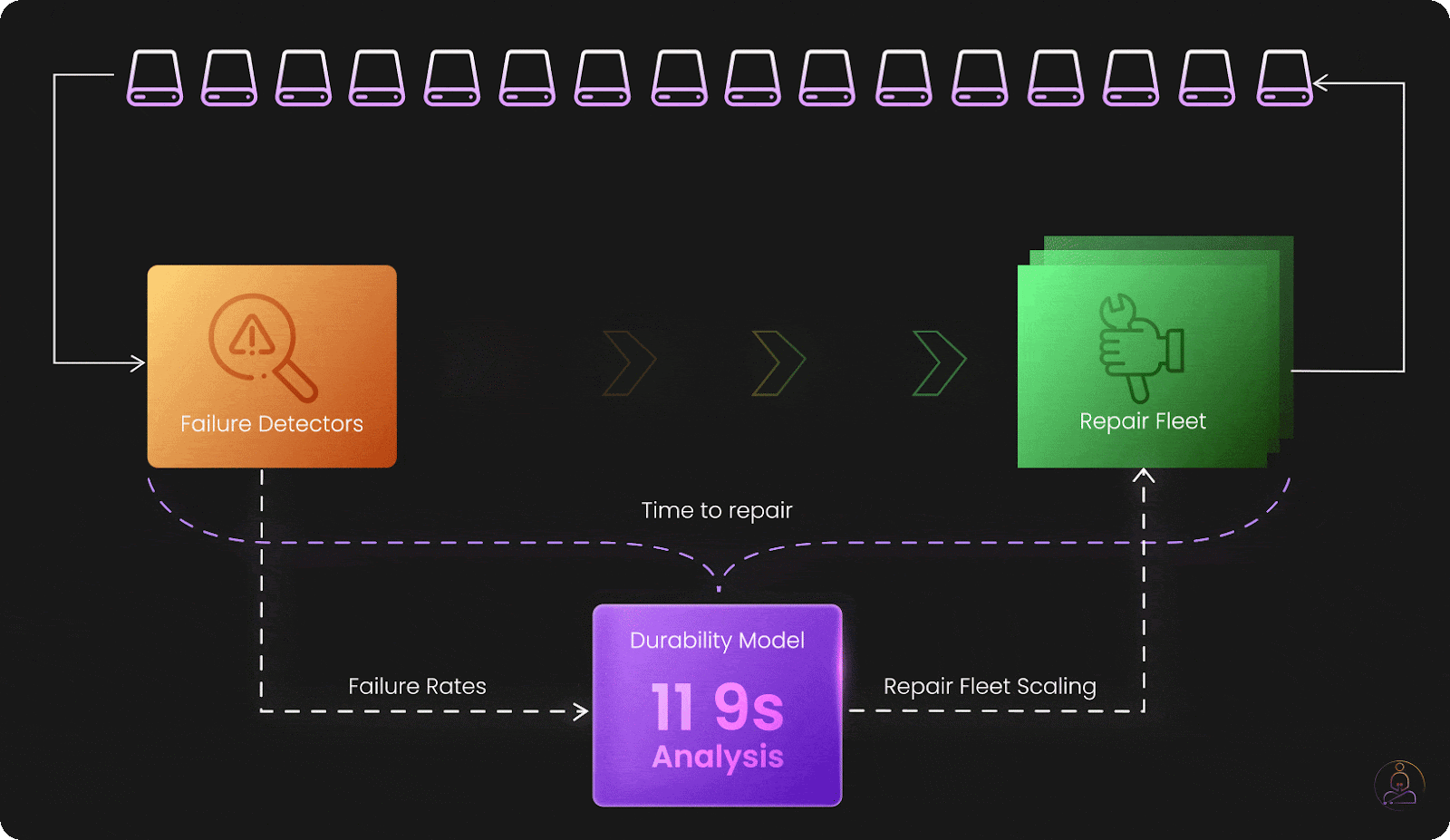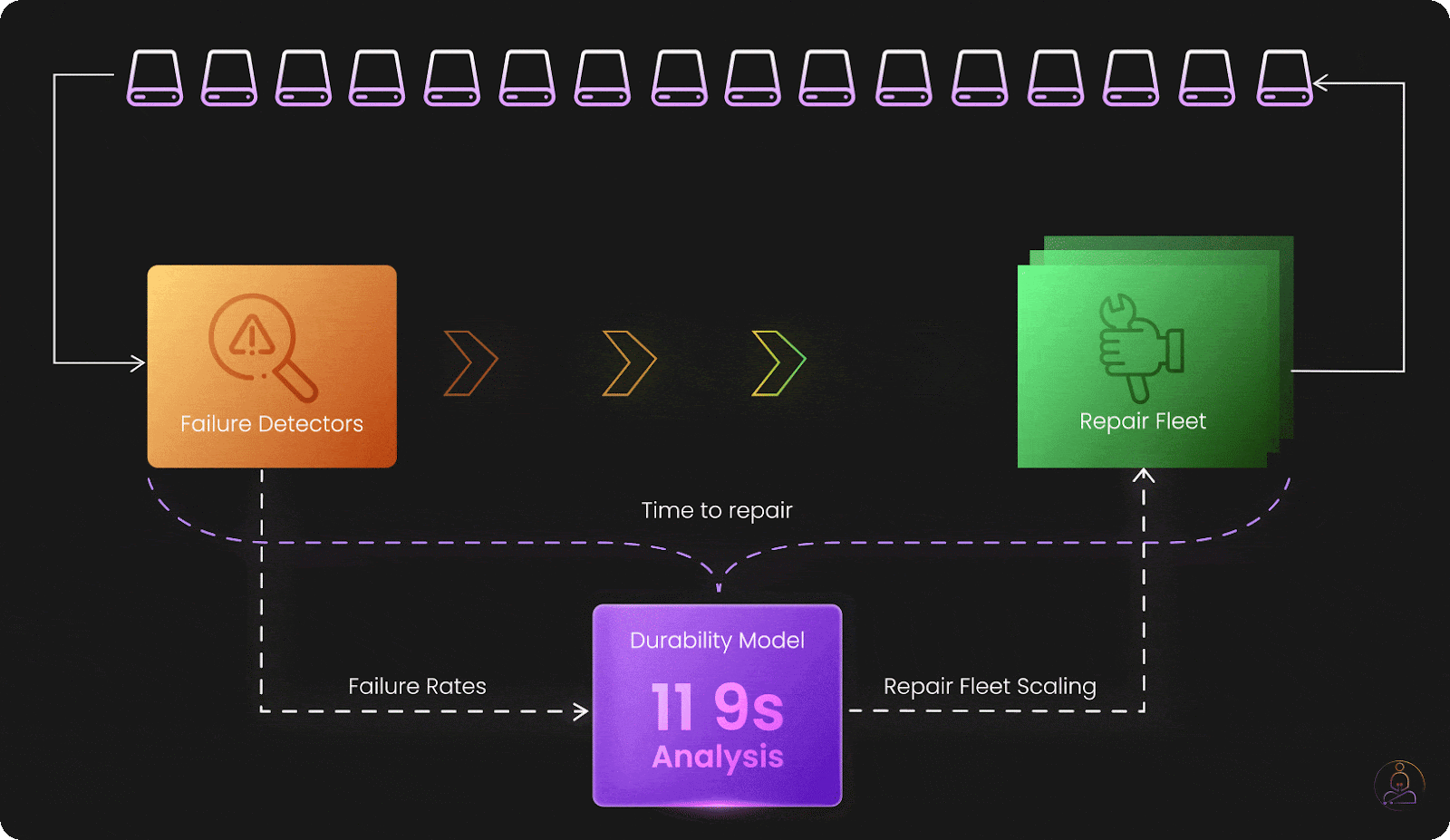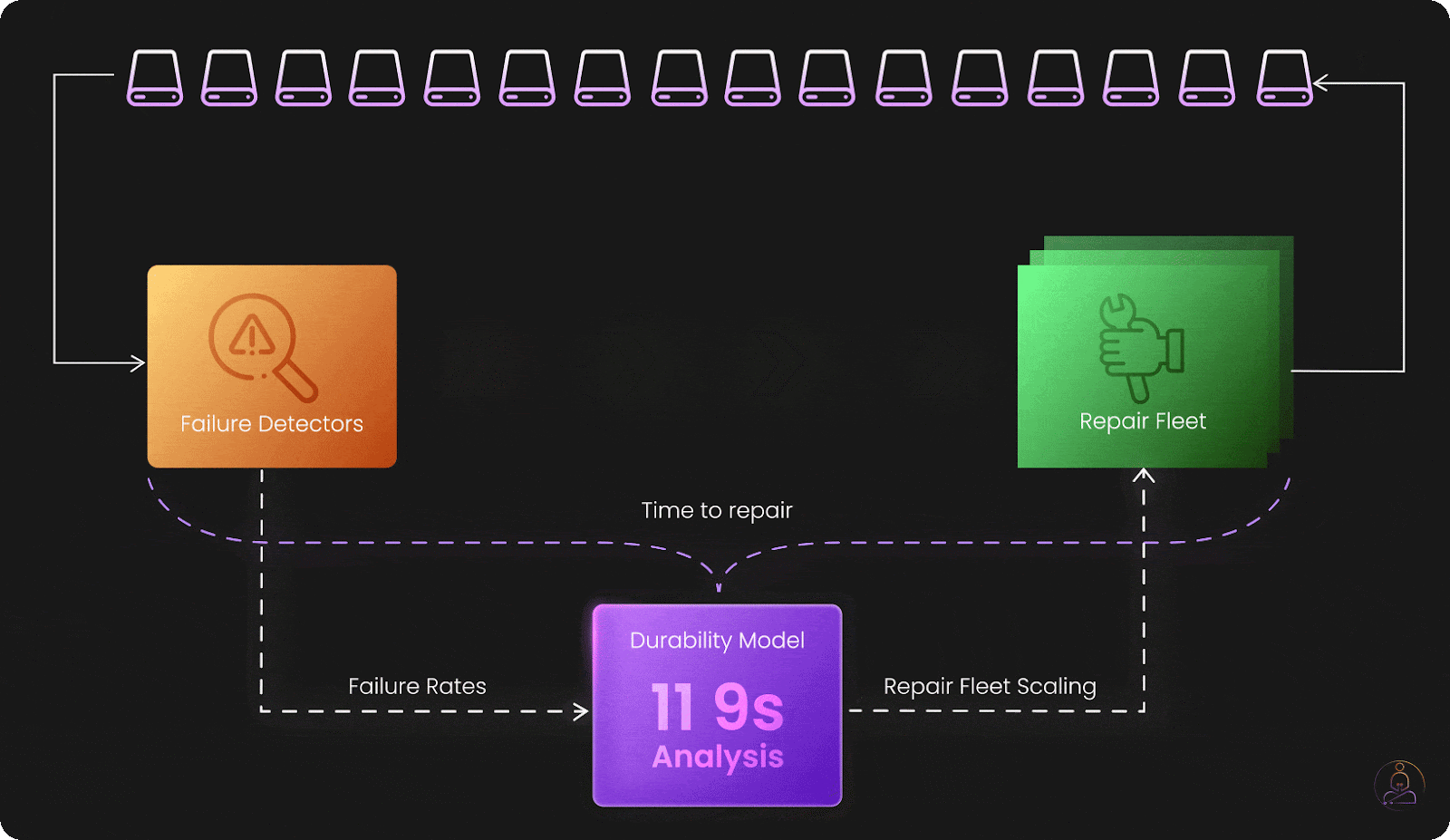
S3 continuously monitors every storage device, tracking metrics like read/write latency, error rates, and performance degradation. When a disk shows signs of trouble, automated systems begin moving data to healthy storage before the device actually fails.
Here's where S3's architecture gets particularly clever: each storage device doesn't run at full capacity. Every disk reserves some free space specifically for recovery operations. When a drive fails, the recovery process doesn't burden just one or two replacement drives. Instead, a swarm of drives across the system contributes small amounts of their reserved capacity to the reconstruction effort.
This distributed recovery approach means that data restoration happens in parallel across hundreds or thousands of drives simultaneously. It's like having a traffic jam suddenly gain dozens of new lanes, the data flows quickly and efficiently to its new home.
The speed of this recovery process is crucial because it affects the window of vulnerability. The faster S3 can restore full redundancy after a failure, the lower the risk of additional failures affecting the same data. The system is designed to keep recovery speed ahead of failure speed, even during periods of elevated hardware problems.
Checksums
Protecting against hardware failure is only part of the durability challenge. Data can also become corrupted in subtler ways, a cosmic ray flips a bit in memory, a network error corrupts bytes in transit, or a software bug introduces corruption during processing.
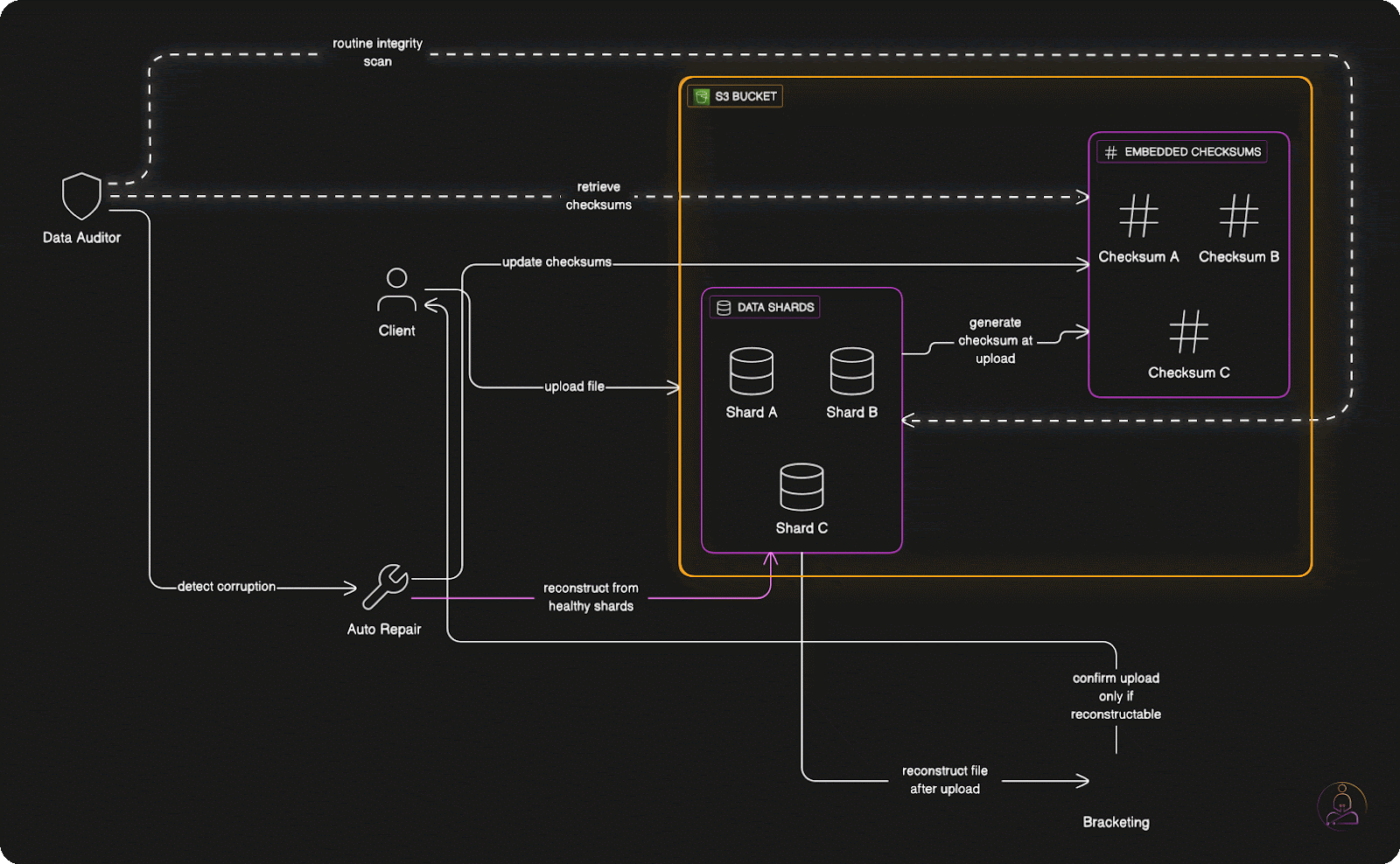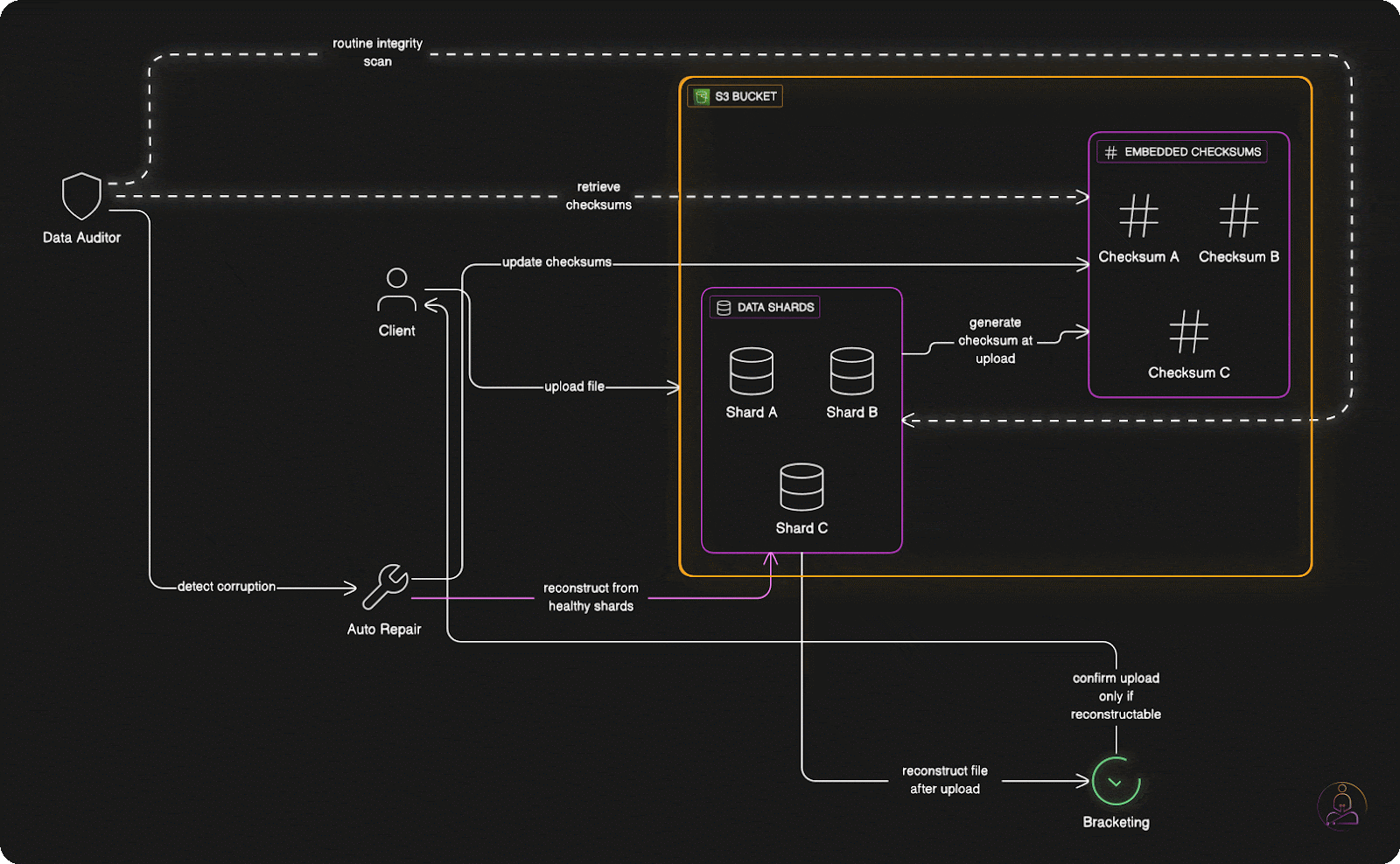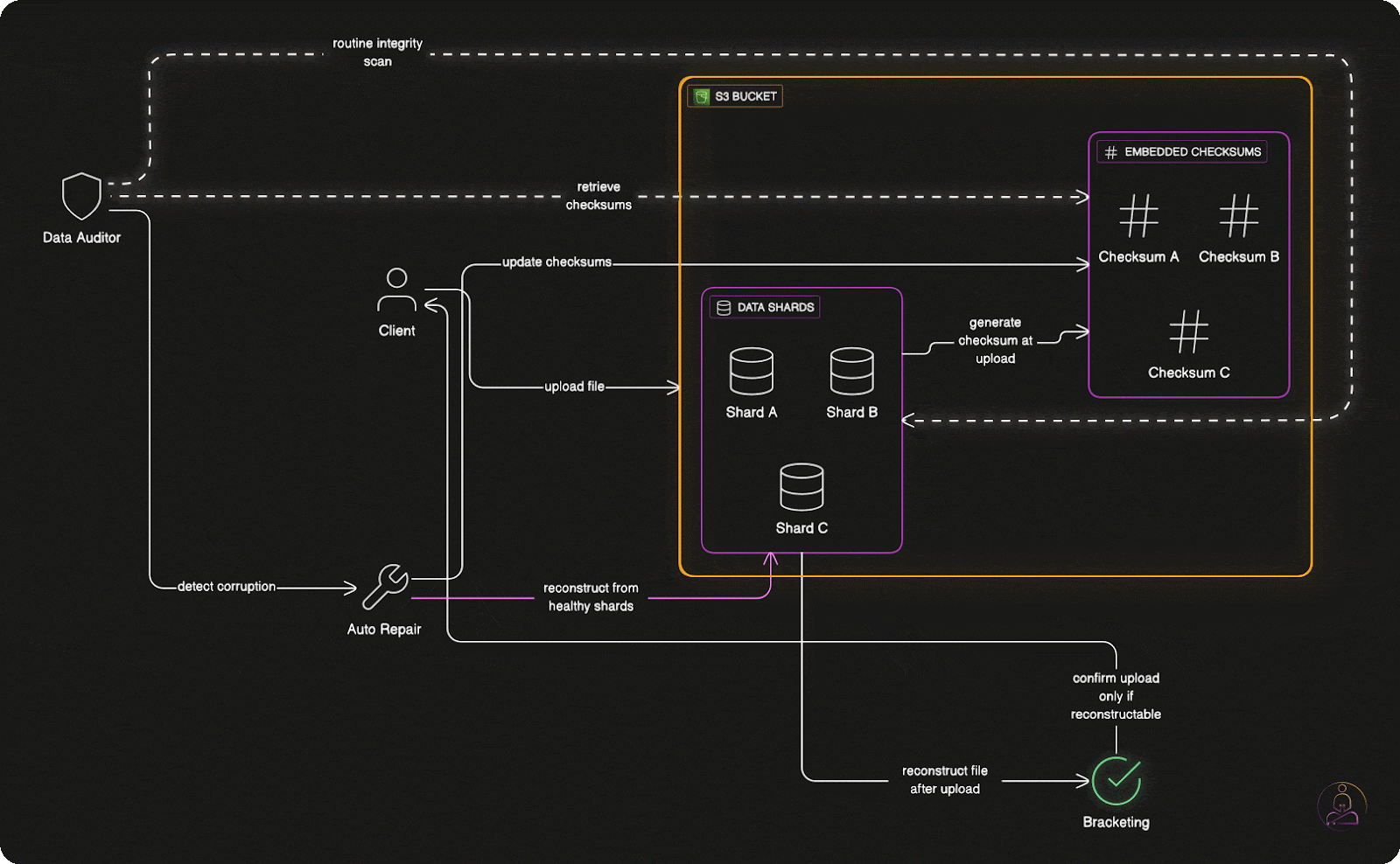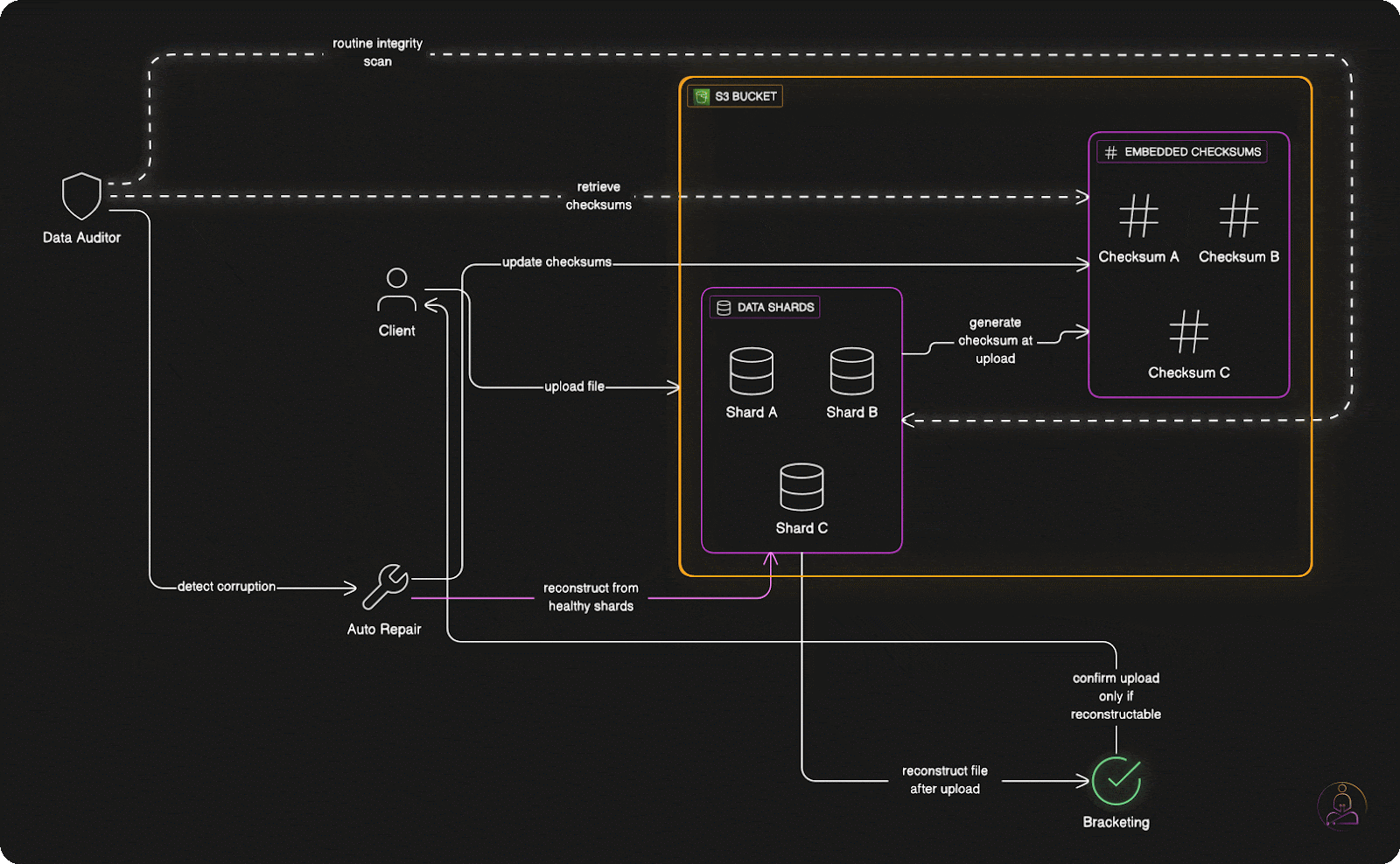
S3 addresses this through comprehensive checksum verification.
Think of a checksum as a digital fingerprint for your data. When you upload a file, S3 calculates a unique mathematical signature based on the exact contents of your data. Even changing a single bit produces a completely different checksum.
But S3 doesn't just calculate checksums once during upload. The system continuously verifies data integrity through background scanning processes. Each erasure-coded shard has its own embedded checksum, and S3 routinely validates these checksums across its entire storage fleet.
When the system detects corruption in a shard, it doesn't panic or alert operations teams. Instead, it quietly reconstructs the corrupted shard from healthy replicas using erasure coding, then replaces the bad data with the corrected version. This healing process happens automatically and transparently, maintaining data integrity without human intervention.
This continuous auditing and automatic repair creates a self-healing storage system that becomes more reliable over time, not less reliable as components age.
Bracketing
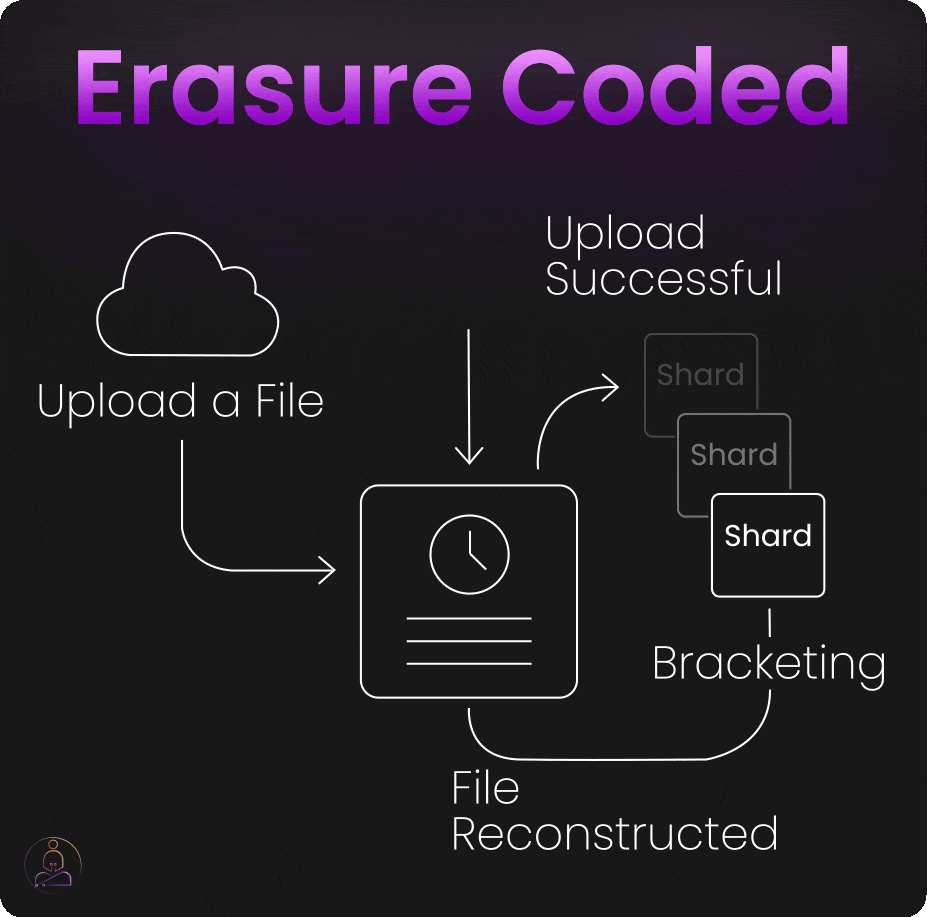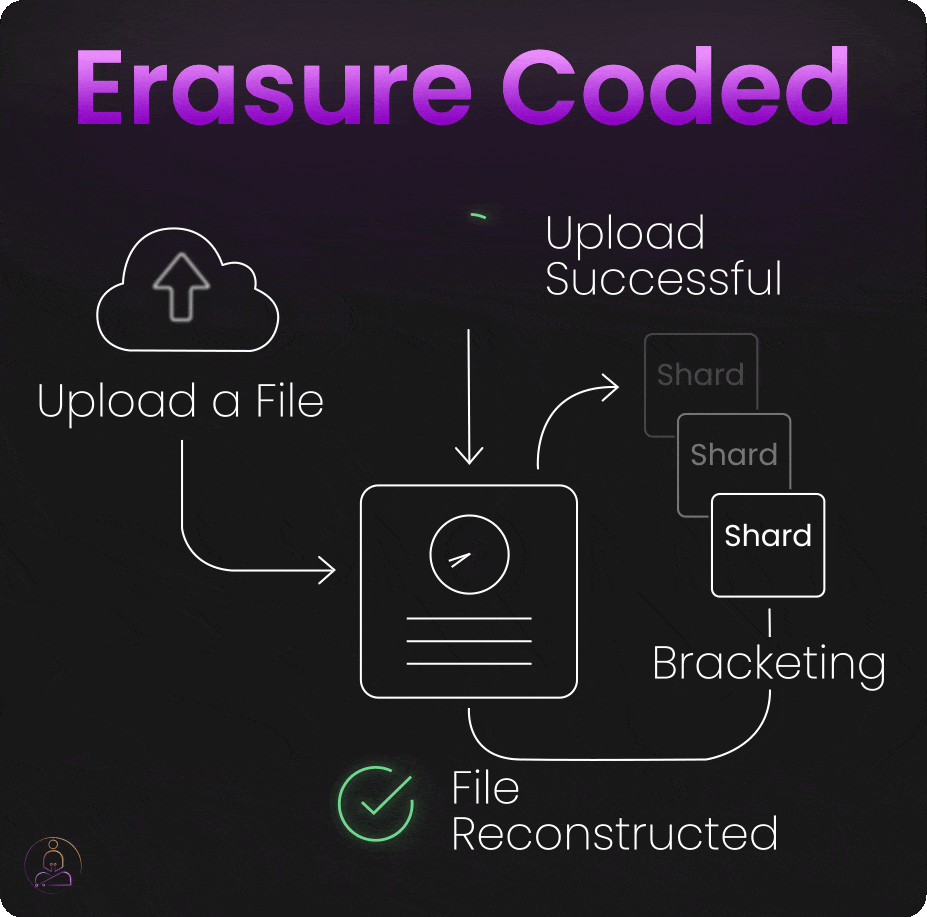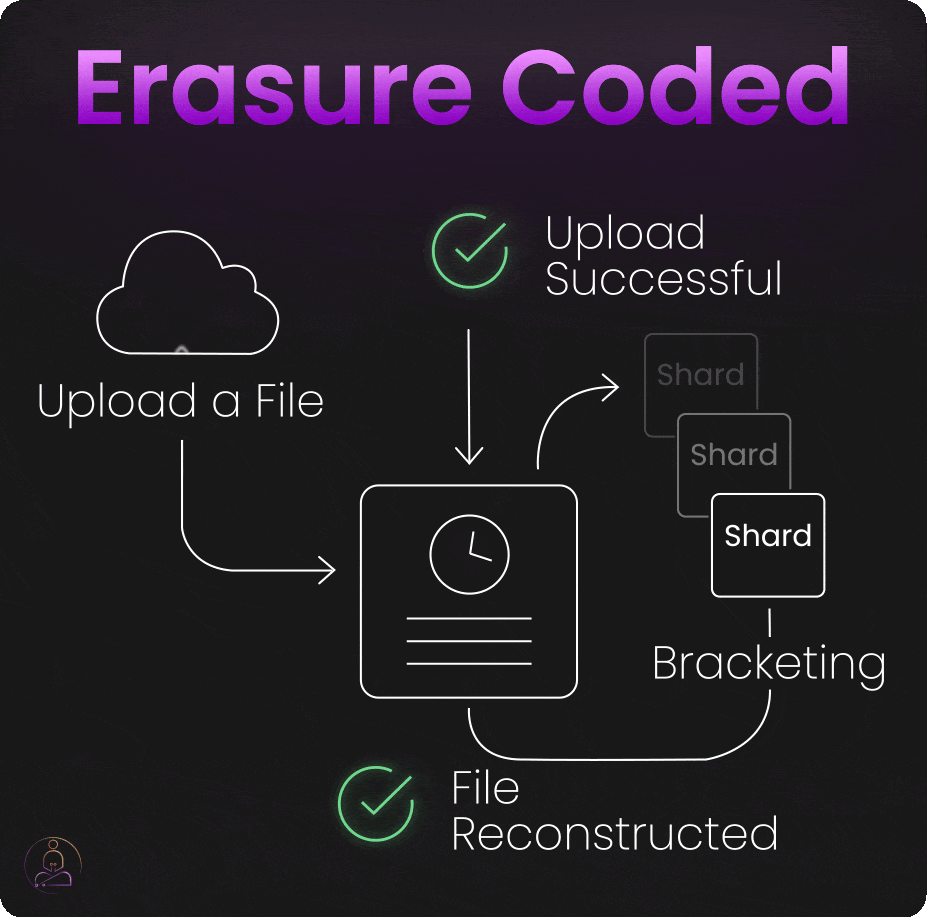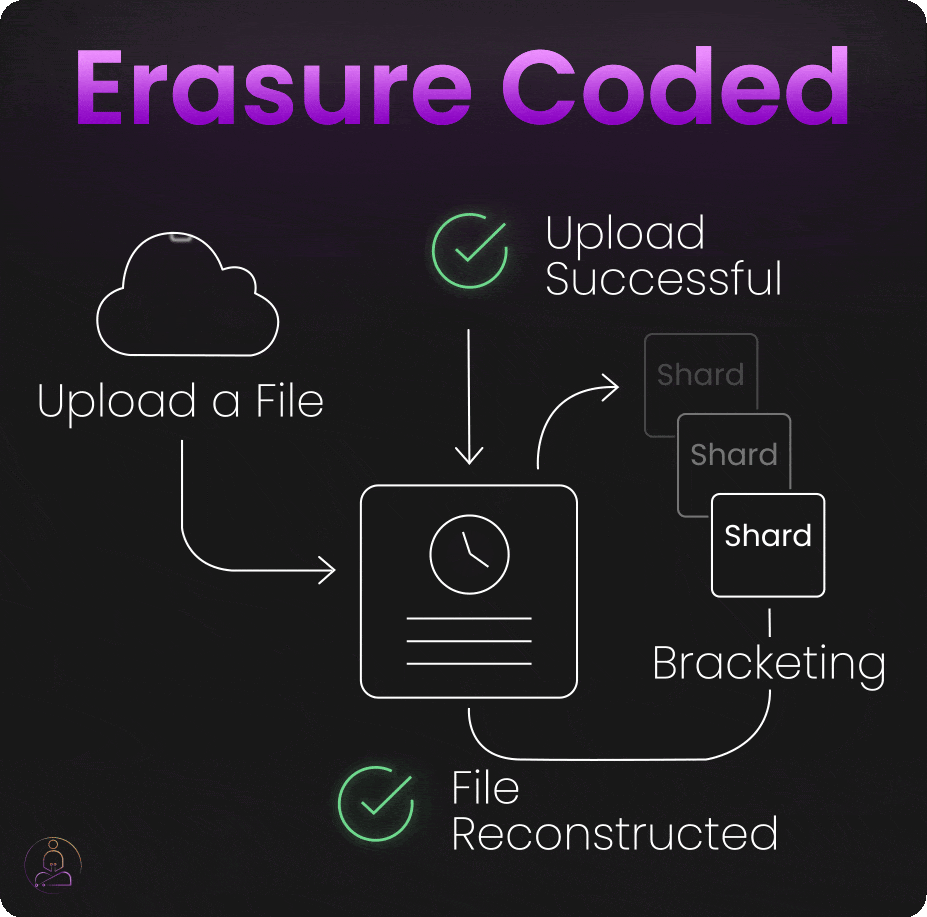
When you upload a file to S3, the system doesn't immediately respond with "upload successful" once the data hits storage devices.
Instead, S3 performs "bracketing", it attempts to reconstruct your original file from the erasure-coded shards it just created. Only if this reconstruction succeeds perfectly does S3 confirm that your upload was successful.
This extra verification step catches problems that might otherwise go unnoticed until you actually need to retrieve your data. By testing recoverability immediately, S3 ensures that every successful upload is genuinely recoverable.
The bracketing process adds slight latency to upload operations, but it provides enormous confidence in data durability. When S3 says your data is safely stored, it has literally proven that claim by reconstructing your file from its stored components.
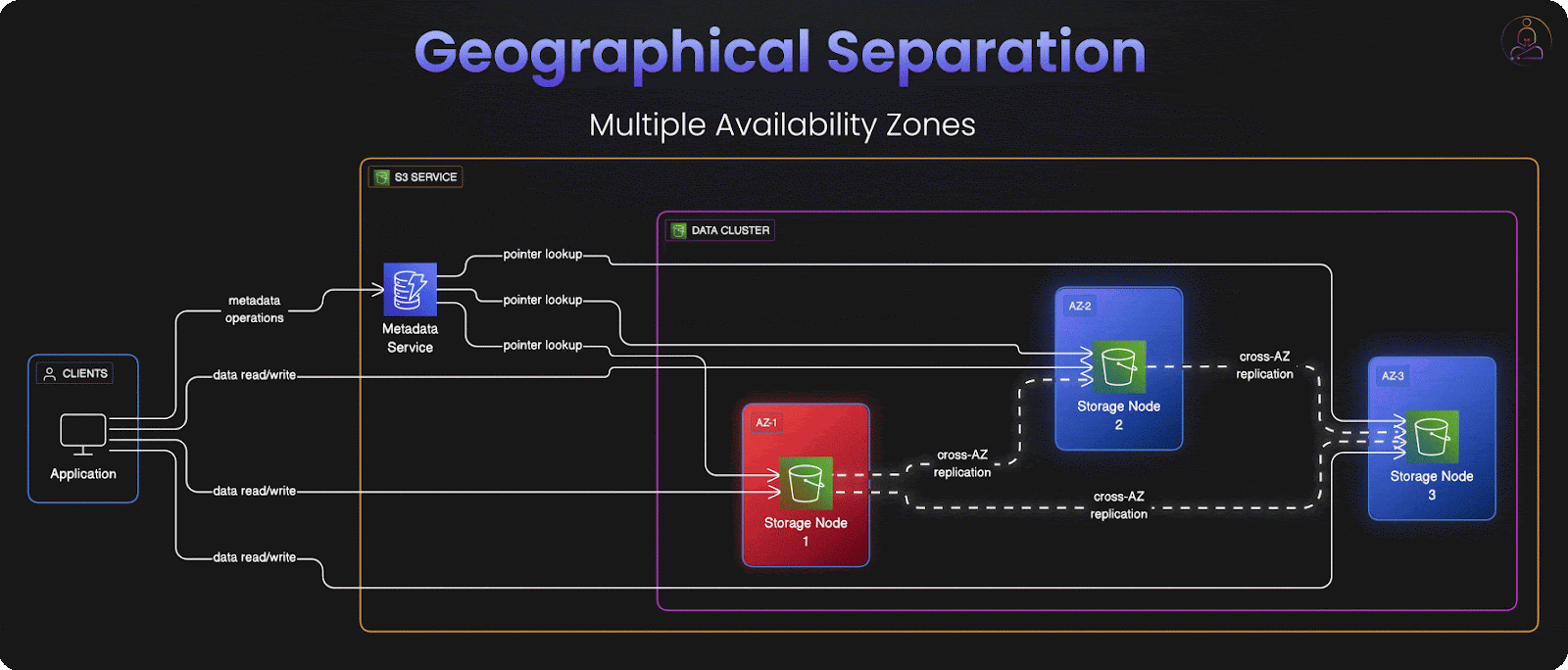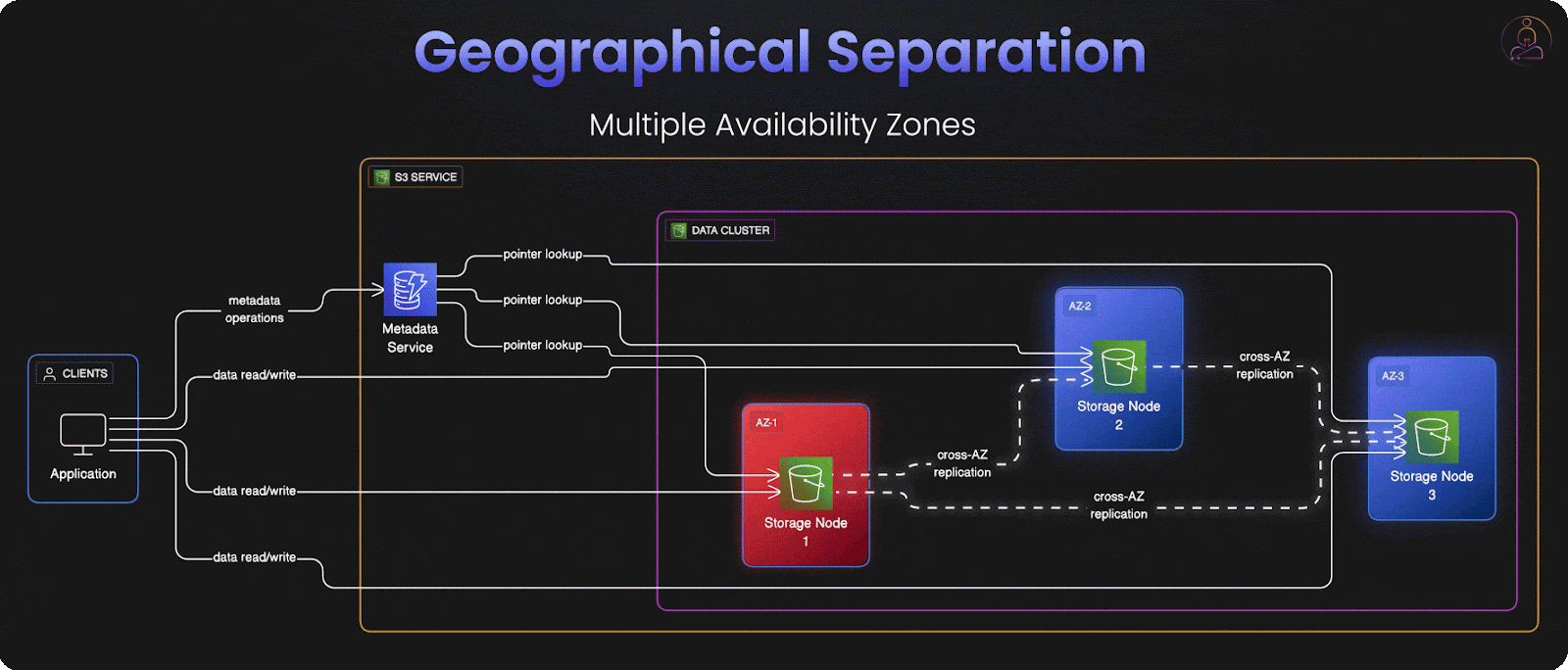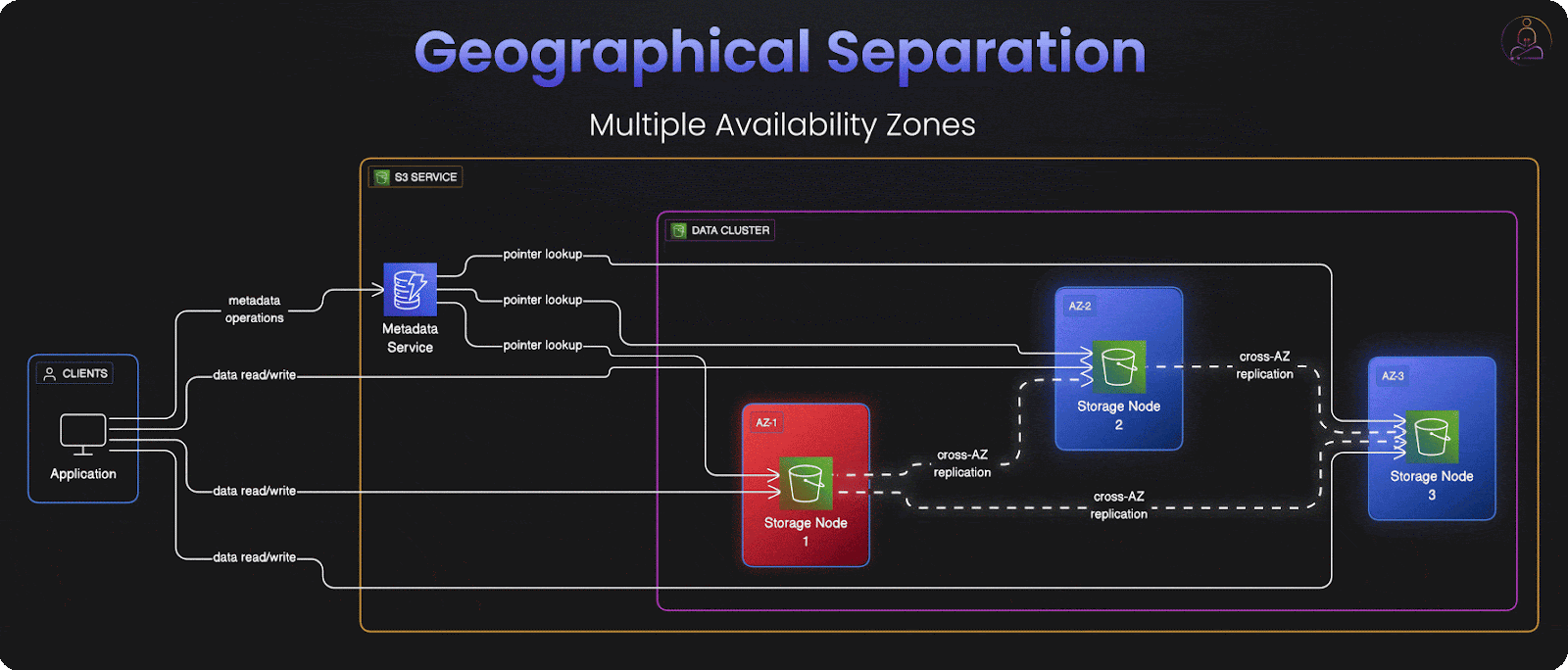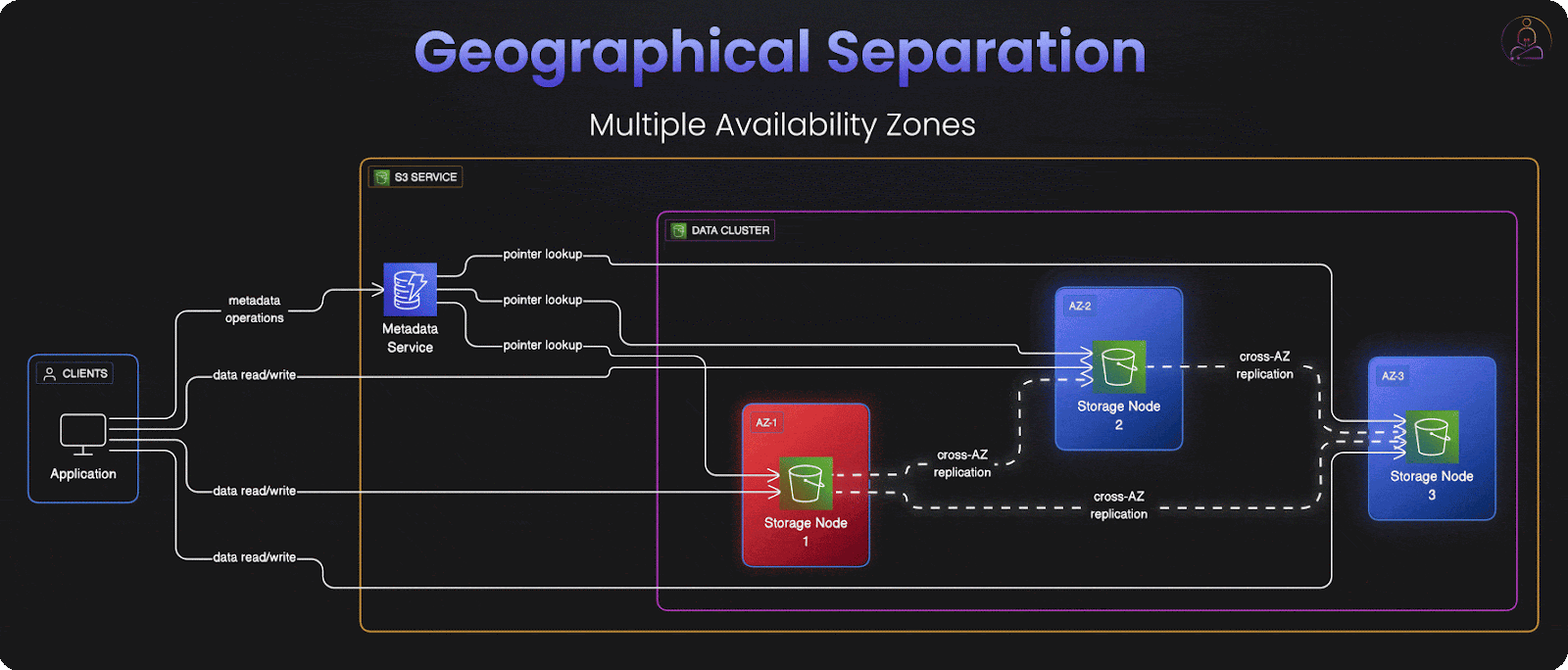
S3's durability strategy extends beyond individual hardware failures to consider larger-scale disasters. Data is distributed not just across different storage devices, but across multiple availability zones that are physically separated by miles within each AWS region.
Each availability zone operates as an independent failure domain with separate power grids, network connections, and cooling systems.
The zones are far enough apart that localized disasters, fires, floods, power grid failures can't affect multiple zones simultaneously, but close enough that network latency between zones remains minimal.
For customers requiring even greater protection, S3 offers cross-region replication, where data is automatically copied to entirely different geographic regions. This protects against region-wide disasters and provides additional options for disaster recovery planning.
The geographic distribution also helps with performance optimization. When you request data, S3 can serve it from the closest available location, reducing latency while maintaining the same durability guarantees.
Human Error Protection
Versioning and Access Controls
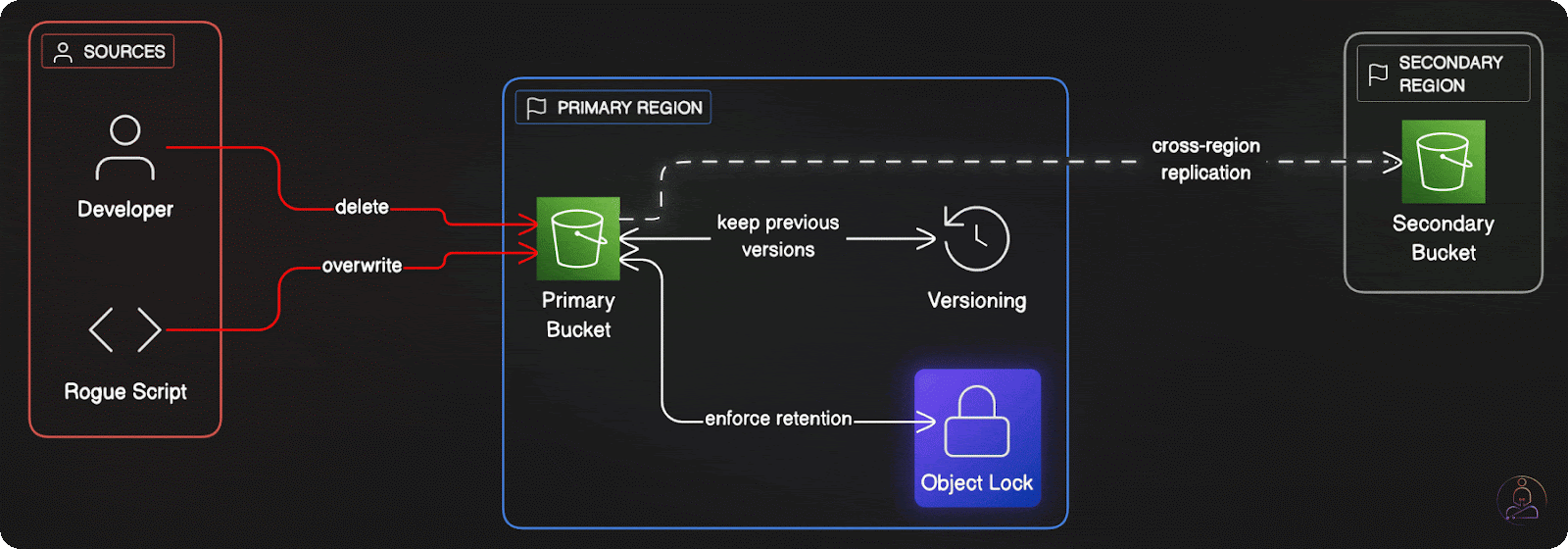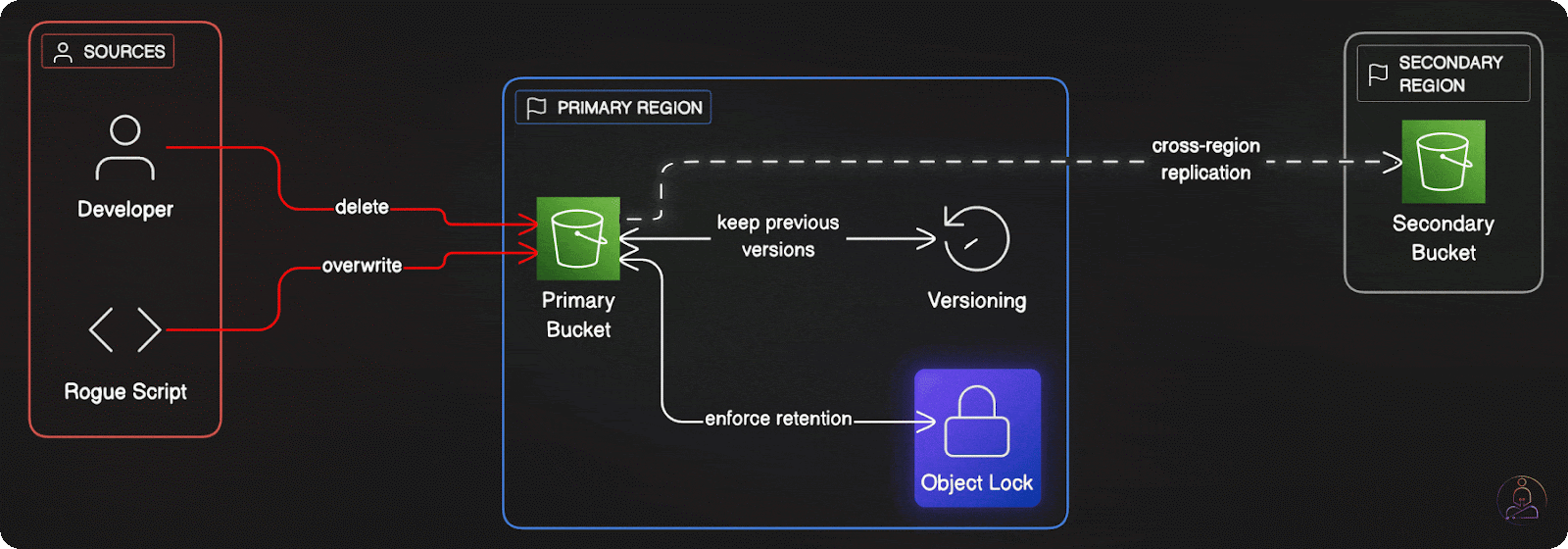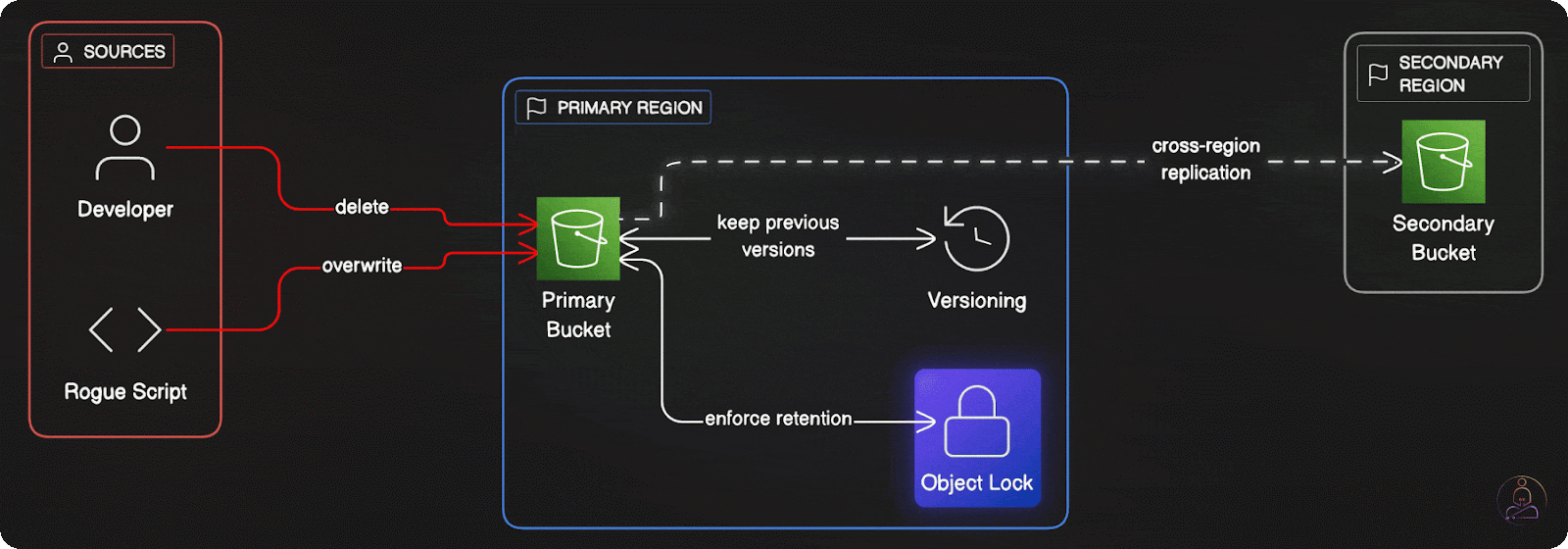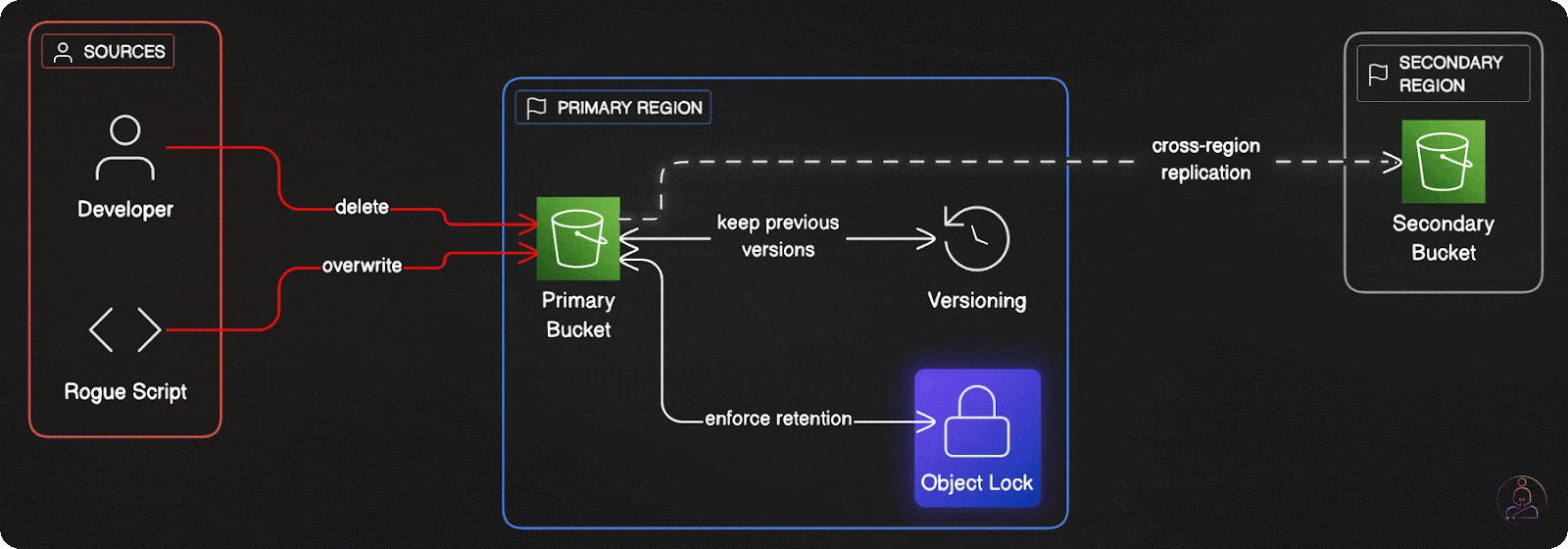
Not all data loss comes from hardware failures or natural disasters. Human errors such as accidental deletions, incorrect overwrites, malicious actions by compromised accounts, represent a significant threat to data durability.
S3 addresses these risks through several complementary features. Object versioning maintains multiple versions of objects automatically, so accidentally overwriting or deleting a file doesn't destroy previous versions. The data remains accessible, and you can restore earlier versions when needed.
Object Lock provides even stronger protection by making objects immutable for specified time periods. Even users with administrative access cannot delete or modify locked objects until the retention period expires. This feature proves particularly valuable for compliance requirements and protecting against ransomware attacks.
Multi-factor authentication and detailed access logging provide additional layers of protection against unauthorized access. S3 can track exactly who accessed what data when, making it easier to detect suspicious activity and understand the scope of any security incidents.
Perhaps the most important factor in S3's durability isn't visible in any architecture diagram: the engineering culture and processes that govern how the system evolves.
Every change to S3, new features, configuration updates, infrastructure modifications, undergoes rigorous durability review. Engineers must demonstrate that their changes won't compromise data protection, even under failure scenarios. This includes modeling worst-case situations, running simulations, and proving that the eleven nines target remains achievable.
Amazon S3's eleven nines of durability isn't just a marketing claim, it's the result of thoughtful engineering, careful implementation, and disciplined operations at massive scale. The system combines multiple layers of protection, from mathematical redundancy through proactive monitoring to comprehensive testing, creating a storage platform that approaches theoretical perfection in data preservation.
For organizations evaluating storage solutions, S3's approach provides a benchmark for what's possible with modern engineering. For system designers, it offers a case study in building reliable systems through principled architecture rather than hoping that individual components won't fail.
The next time you upload a file to the cloud and trust that it will be there years from now, remember that this seemingly simple act relies on some of the most sophisticated reliability engineering ever deployed at scale. It's a reminder that behind every effortless user experience lies extraordinary technical complexity, working invisibly to keep our digital world running.
Really sumptuous article. Thanks for posting.
Great Article